

Fix fused add rms norm (#4)
Browse files* make fused add rms norm return 2 outputs
* add builds
* add plot
---------
Co-authored-by: taehyun <[email protected]>
This view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +4 -2
- activation/fused_add_rms_norm.cu +221 -3
- activation/fused_mul_poly_norm.cu +4 -4
- benchmarks/cases/add_rms.py +2 -1
- benchmarks/common/bench_framework.py +8 -2
- benchmarks/common/diff_engine.py +4 -1
- benchmarks/plots/h100/add_rms/plot_add_rms-bwd-perf.png +0 -0
- benchmarks/plots/h100/add_rms/plot_add_rms-fwd-perf.png +0 -0
- benchmarks/plots/h100/mul_poly/plot_mul_poly-bwd-perf.png +0 -0
- benchmarks/plots/h100/mul_poly/plot_mul_poly-fwd-perf.png +0 -0
- benchmarks/plots/h100/poly/plot_poly-bwd-perf.png +0 -0
- benchmarks/plots/h100/poly/plot_poly-fwd-perf.png +0 -0
- benchmarks/plots/h100/rms/plot_rms-bwd-perf.png +0 -0
- benchmarks/plots/h100/rms/plot_rms-fwd-perf.png +0 -0
- benchmarks/plots/mi250/add_rms/plot_add_rms-bwd-perf.png +0 -0
- benchmarks/plots/mi250/add_rms/plot_add_rms-fwd-perf.png +0 -0
- build/torch27-cxx11-cu118-x86_64-linux/activation/__init__.py +1 -1
- build/torch27-cxx11-cu118-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so +3 -0
- build/torch27-cxx11-cu118-x86_64-linux/activation/_ops.py +3 -3
- build/torch27-cxx11-cu118-x86_64-linux/activation/layers.py +1 -1
- build/torch27-cxx11-cu118-x86_64-linux/activation/rms_norm.py +2 -8
- build/torch27-cxx11-cu126-x86_64-linux/activation/__init__.py +1 -1
- build/torch27-cxx11-cu126-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so +3 -0
- build/torch27-cxx11-cu126-x86_64-linux/activation/_ops.py +3 -3
- build/torch27-cxx11-cu126-x86_64-linux/activation/layers.py +1 -1
- build/torch27-cxx11-cu126-x86_64-linux/activation/rms_norm.py +2 -8
- build/torch27-cxx11-cu128-x86_64-linux/activation/__init__.py +1 -1
- build/torch27-cxx11-cu128-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so +3 -0
- build/torch27-cxx11-cu128-x86_64-linux/activation/_ops.py +3 -3
- build/torch27-cxx11-cu128-x86_64-linux/activation/layers.py +1 -1
- build/torch27-cxx11-cu128-x86_64-linux/activation/rms_norm.py +2 -8
- build/torch27-cxx11-rocm63-x86_64-linux/activation/__init__.py +1 -1
- build/torch27-cxx11-rocm63-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so +3 -0
- build/torch27-cxx11-rocm63-x86_64-linux/activation/_ops.py +3 -3
- build/torch27-cxx11-rocm63-x86_64-linux/activation/layers.py +1 -1
- build/torch27-cxx11-rocm63-x86_64-linux/activation/rms_norm.py +2 -8
- build/torch28-cxx11-cu126-x86_64-linux/activation/__init__.py +1 -1
- build/torch28-cxx11-cu126-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so +3 -0
- build/torch28-cxx11-cu126-x86_64-linux/activation/_ops.py +3 -3
- build/torch28-cxx11-cu126-x86_64-linux/activation/layers.py +1 -1
- build/torch28-cxx11-cu126-x86_64-linux/activation/rms_norm.py +2 -8
- build/torch28-cxx11-cu128-x86_64-linux/activation/__init__.py +1 -1
- build/torch28-cxx11-cu128-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so +3 -0
- build/torch28-cxx11-cu128-x86_64-linux/activation/_ops.py +3 -3
- build/torch28-cxx11-cu128-x86_64-linux/activation/layers.py +1 -1
- build/torch28-cxx11-cu128-x86_64-linux/activation/rms_norm.py +2 -8
- build/torch28-cxx11-cu129-x86_64-linux/activation/__init__.py +1 -1
- build/torch28-cxx11-cu129-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so +3 -0
- build/torch28-cxx11-cu129-x86_64-linux/activation/_ops.py +3 -3
- build/torch28-cxx11-cu129-x86_64-linux/activation/layers.py +1 -1
README.md
CHANGED
|
@@ -18,13 +18,15 @@ Activation is a python package that contains custom CUDA-based activation kernel
|
|
| 18 |
|
| 19 |
```python
|
| 20 |
y = x + residual
|
| 21 |
-
|
|
|
|
| 22 |
```
|
| 23 |
|
| 24 |
- Fused as:
|
| 25 |
|
| 26 |
```python
|
| 27 |
-
|
|
|
|
| 28 |
```
|
| 29 |
|
| 30 |
- **FusedMulPolyNorm**
|
|
|
|
| 18 |
|
| 19 |
```python
|
| 20 |
y = x + residual
|
| 21 |
+
hidden_state = rms_norm(y, weight, eps)
|
| 22 |
+
out = y + some_op(hidden_state)
|
| 23 |
```
|
| 24 |
|
| 25 |
- Fused as:
|
| 26 |
|
| 27 |
```python
|
| 28 |
+
hidden_state, y = fused_add_rms_norm(x, residual, weight, eps)
|
| 29 |
+
out = y + some_op(hidden_state)
|
| 30 |
```
|
| 31 |
|
| 32 |
- **FusedMulPolyNorm**
|
activation/fused_add_rms_norm.cu
CHANGED
|
@@ -117,9 +117,175 @@ fused_add_rms_norm_kernel(scalar_t *__restrict__ out, // [..., d]
|
|
| 117 |
}
|
| 118 |
}
|
| 119 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 120 |
} // namespace motif
|
| 121 |
|
| 122 |
-
#define
|
| 123 |
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 124 |
input.scalar_type(), "fused_add_rms_norm_kernel", [&] { \
|
| 125 |
motif::fused_add_rms_norm_kernel<scalar_t, float, width> \
|
|
@@ -150,8 +316,60 @@ void fused_add_rms_norm(torch::Tensor &out, // [..., d]
|
|
| 150 |
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 151 |
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 152 |
if (d % 8 == 0) {
|
| 153 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 154 |
} else {
|
| 155 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 156 |
}
|
| 157 |
}
|
|
|
|
| 117 |
}
|
| 118 |
}
|
| 119 |
|
| 120 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 121 |
+
__global__ std::enable_if_t<(width > 0)> fused_add_rms_norm_backward_kernel(
|
| 122 |
+
scalar_t *__restrict__ input_grad, // [..., d]
|
| 123 |
+
acc_t *__restrict__ temp_weight_grad, // [..., d]
|
| 124 |
+
const scalar_t *__restrict__ output_grad, // [..., d]
|
| 125 |
+
const scalar_t *__restrict__ add_output_grad, // [..., d]
|
| 126 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 127 |
+
const scalar_t *__restrict__ weight, // [d]
|
| 128 |
+
const float eps, const int d) {
|
| 129 |
+
using vec_t = type_vec_t<scalar_t, width>;
|
| 130 |
+
using dw_vec_t = type_vec_t<acc_t, width>;
|
| 131 |
+
|
| 132 |
+
const int64_t token_idx = blockIdx.x;
|
| 133 |
+
const int64_t vec_idx = threadIdx.x;
|
| 134 |
+
|
| 135 |
+
const int vec_d = d / width;
|
| 136 |
+
const int64_t vec_offset = token_idx * vec_d;
|
| 137 |
+
|
| 138 |
+
const vec_t *__restrict__ input_vec = reinterpret_cast<const vec_t *>(input);
|
| 139 |
+
const vec_t *__restrict__ output_grad_vec =
|
| 140 |
+
reinterpret_cast<const vec_t *>(output_grad);
|
| 141 |
+
const vec_t *__restrict__ weight_vec =
|
| 142 |
+
reinterpret_cast<const vec_t *>(weight);
|
| 143 |
+
|
| 144 |
+
acc_t d_sum = 0.0f;
|
| 145 |
+
acc_t sum_square = 0.0f;
|
| 146 |
+
|
| 147 |
+
for (int64_t vidx = vec_idx; vidx < vec_d; vidx += blockDim.x) {
|
| 148 |
+
vec_t x_vec = input_vec[vec_offset + vidx];
|
| 149 |
+
vec_t dy_vec = output_grad_vec[vec_offset + vidx];
|
| 150 |
+
vec_t w_vec = weight_vec[vidx];
|
| 151 |
+
|
| 152 |
+
#pragma unroll
|
| 153 |
+
for (int i = 0; i < width; ++i) {
|
| 154 |
+
acc_t x = x_vec.data[i];
|
| 155 |
+
acc_t dy = dy_vec.data[i];
|
| 156 |
+
acc_t w = w_vec.data[i];
|
| 157 |
+
d_sum += dy * x * w;
|
| 158 |
+
sum_square += x * x;
|
| 159 |
+
}
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
using BlockReduce = cub::BlockReduce<float2, 1024>;
|
| 163 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 164 |
+
struct SumOp {
|
| 165 |
+
__device__ float2 operator()(const float2 &a, const float2 &b) const {
|
| 166 |
+
return make_float2(a.x + b.x, a.y + b.y);
|
| 167 |
+
}
|
| 168 |
+
};
|
| 169 |
+
float2 thread_sums = make_float2(d_sum, sum_square);
|
| 170 |
+
float2 block_sums =
|
| 171 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 172 |
+
|
| 173 |
+
d_sum = block_sums.x;
|
| 174 |
+
sum_square = block_sums.y;
|
| 175 |
+
|
| 176 |
+
__shared__ acc_t s_scale;
|
| 177 |
+
__shared__ acc_t s_dxx;
|
| 178 |
+
|
| 179 |
+
if (threadIdx.x == 0) {
|
| 180 |
+
acc_t scale = rsqrtf(sum_square / d + eps);
|
| 181 |
+
s_dxx = d_sum * scale * scale * scale / d;
|
| 182 |
+
s_scale = scale;
|
| 183 |
+
}
|
| 184 |
+
__syncthreads();
|
| 185 |
+
acc_t scale = s_scale;
|
| 186 |
+
acc_t dxx = s_dxx;
|
| 187 |
+
vec_t *__restrict__ input_grad_vec = reinterpret_cast<vec_t *>(input_grad);
|
| 188 |
+
dw_vec_t *__restrict__ temp_weight_grad_vec =
|
| 189 |
+
reinterpret_cast<dw_vec_t *>(temp_weight_grad);
|
| 190 |
+
const vec_t *__restrict__ add_output_grad_vec =
|
| 191 |
+
reinterpret_cast<const vec_t *>(add_output_grad);
|
| 192 |
+
|
| 193 |
+
for (int64_t vidx = vec_idx; vidx < vec_d; vidx += blockDim.x) {
|
| 194 |
+
vec_t x_vec = input_vec[vec_offset + vidx];
|
| 195 |
+
vec_t dy_vec = output_grad_vec[vec_offset + vidx];
|
| 196 |
+
vec_t da_vec = add_output_grad_vec[vec_offset + vidx];
|
| 197 |
+
vec_t w_vec = weight_vec[vidx];
|
| 198 |
+
|
| 199 |
+
vec_t in_grad_vec;
|
| 200 |
+
dw_vec_t tw_grad_vec;
|
| 201 |
+
|
| 202 |
+
#pragma unroll
|
| 203 |
+
for (int i = 0; i < width; ++i) {
|
| 204 |
+
acc_t x = x_vec.data[i];
|
| 205 |
+
acc_t dy = dy_vec.data[i];
|
| 206 |
+
acc_t w = w_vec.data[i];
|
| 207 |
+
|
| 208 |
+
if (input_grad) {
|
| 209 |
+
scalar_t da = da_vec.data[i];
|
| 210 |
+
scalar_t in_grad = scale * dy * w - dxx * x;
|
| 211 |
+
in_grad_vec.data[i] = in_grad + da;
|
| 212 |
+
}
|
| 213 |
+
tw_grad_vec.data[i] = dy * x * scale;
|
| 214 |
+
}
|
| 215 |
+
|
| 216 |
+
if (input_grad) {
|
| 217 |
+
input_grad_vec[vec_offset + vidx] = in_grad_vec;
|
| 218 |
+
}
|
| 219 |
+
temp_weight_grad_vec[vec_offset + vidx] = tw_grad_vec;
|
| 220 |
+
}
|
| 221 |
+
}
|
| 222 |
+
|
| 223 |
+
template <typename scalar_t, typename acc_t, int width>
|
| 224 |
+
__global__ std::enable_if_t<(width == 0)> fused_add_rms_norm_backward_kernel(
|
| 225 |
+
scalar_t *__restrict__ input_grad, // [..., d]
|
| 226 |
+
acc_t *__restrict__ temp_weight_grad, // [..., d]
|
| 227 |
+
const scalar_t *__restrict__ output_grad, // [..., d]
|
| 228 |
+
const scalar_t *__restrict__ add_output_grad, // [..., d]
|
| 229 |
+
const scalar_t *__restrict__ input, // [..., d]
|
| 230 |
+
const scalar_t *__restrict__ weight, // [d]
|
| 231 |
+
const float eps, const int d) {
|
| 232 |
+
const int64_t token_idx = blockIdx.x;
|
| 233 |
+
const int64_t vec_idx = threadIdx.x;
|
| 234 |
+
acc_t d_sum = 0.0f;
|
| 235 |
+
acc_t sum_square = 0.0f;
|
| 236 |
+
|
| 237 |
+
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 238 |
+
acc_t x = input[token_idx * d + idx];
|
| 239 |
+
acc_t dy = output_grad[token_idx * d + idx];
|
| 240 |
+
acc_t w = weight[idx];
|
| 241 |
+
d_sum += dy * x * w;
|
| 242 |
+
sum_square += x * x;
|
| 243 |
+
}
|
| 244 |
+
|
| 245 |
+
using BlockReduce = cub::BlockReduce<float2, 1024>;
|
| 246 |
+
__shared__ typename BlockReduce::TempStorage reduceStore;
|
| 247 |
+
struct SumOp {
|
| 248 |
+
__device__ float2 operator()(const float2 &a, const float2 &b) const {
|
| 249 |
+
return make_float2(a.x + b.x, a.y + b.y);
|
| 250 |
+
}
|
| 251 |
+
};
|
| 252 |
+
float2 thread_sums = make_float2(d_sum, sum_square);
|
| 253 |
+
float2 block_sums =
|
| 254 |
+
BlockReduce(reduceStore).Reduce(thread_sums, SumOp{}, blockDim.x);
|
| 255 |
+
|
| 256 |
+
d_sum = block_sums.x;
|
| 257 |
+
sum_square = block_sums.y;
|
| 258 |
+
|
| 259 |
+
__shared__ acc_t s_scale;
|
| 260 |
+
__shared__ acc_t s_dxx;
|
| 261 |
+
|
| 262 |
+
if (threadIdx.x == 0) {
|
| 263 |
+
acc_t scale = rsqrtf(sum_square / d + eps);
|
| 264 |
+
s_dxx = d_sum * scale * scale * scale / d;
|
| 265 |
+
s_scale = scale;
|
| 266 |
+
}
|
| 267 |
+
__syncthreads();
|
| 268 |
+
|
| 269 |
+
acc_t scale = s_scale;
|
| 270 |
+
acc_t dxx = s_dxx;
|
| 271 |
+
|
| 272 |
+
for (int64_t idx = vec_idx; idx < d; idx += blockDim.x) {
|
| 273 |
+
acc_t x = input[token_idx * d + idx];
|
| 274 |
+
acc_t dy = output_grad[token_idx * d + idx];
|
| 275 |
+
acc_t w = weight[idx];
|
| 276 |
+
|
| 277 |
+
if (input_grad) {
|
| 278 |
+
scalar_t da = add_output_grad[token_idx * d + idx];
|
| 279 |
+
scalar_t in_grad = scale * dy * w - dxx * x;
|
| 280 |
+
input_grad[token_idx * d + idx] = in_grad + da;
|
| 281 |
+
}
|
| 282 |
+
temp_weight_grad[token_idx * d + idx] = dy * x * scale;
|
| 283 |
+
}
|
| 284 |
+
}
|
| 285 |
+
|
| 286 |
} // namespace motif
|
| 287 |
|
| 288 |
+
#define LAUNCH_FUSED_ADD_RMS_NORM(width) \
|
| 289 |
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 290 |
input.scalar_type(), "fused_add_rms_norm_kernel", [&] { \
|
| 291 |
motif::fused_add_rms_norm_kernel<scalar_t, float, width> \
|
|
|
|
| 316 |
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 317 |
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 318 |
if (d % 8 == 0) {
|
| 319 |
+
LAUNCH_FUSED_ADD_RMS_NORM(8);
|
| 320 |
+
} else {
|
| 321 |
+
LAUNCH_FUSED_ADD_RMS_NORM(0);
|
| 322 |
+
}
|
| 323 |
+
}
|
| 324 |
+
|
| 325 |
+
#define LAUNCH_FUSED_ADD_RMS_NORM_BWD(width) \
|
| 326 |
+
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 327 |
+
input.scalar_type(), "fused_add_rms_norm_backward_kernel", [&] { \
|
| 328 |
+
motif::fused_add_rms_norm_backward_kernel<scalar_t, float, width> \
|
| 329 |
+
<<<grid, block, 0, stream>>>(input_grad.data_ptr<scalar_t>(), \
|
| 330 |
+
temp_weight_grad.data_ptr<float>(), \
|
| 331 |
+
output_grad.data_ptr<scalar_t>(), \
|
| 332 |
+
add_output_grad.data_ptr<scalar_t>(), \
|
| 333 |
+
input.data_ptr<scalar_t>(), \
|
| 334 |
+
weight.data_ptr<scalar_t>(), eps, d); \
|
| 335 |
+
});
|
| 336 |
+
|
| 337 |
+
void fused_add_rms_norm_backward(
|
| 338 |
+
torch::Tensor &input_grad, // [..., d]
|
| 339 |
+
torch::Tensor &weight_grad, // [d]
|
| 340 |
+
const torch::Tensor &output_grad, // [..., d]
|
| 341 |
+
const torch::Tensor &add_output_grad, // [..., d]
|
| 342 |
+
const torch::Tensor &input, // [..., d]
|
| 343 |
+
const torch::Tensor &weight, // [d]
|
| 344 |
+
double eps) {
|
| 345 |
+
AssertTensorShapeEqual(input, input_grad, "input", "input_grad");
|
| 346 |
+
AssertTensorShapeEqual(input, output_grad, "input", "output_grad");
|
| 347 |
+
AssertTensorShapeEqual(input, output_grad, "input", "add_output_grad");
|
| 348 |
+
AssertTensorNotNull(weight, "weight");
|
| 349 |
+
// TODO shape check
|
| 350 |
+
// weight_grad, input_grad can be nullable
|
| 351 |
+
|
| 352 |
+
int d = input.size(-1);
|
| 353 |
+
int64_t num_tokens = input.numel() / input.size(-1);
|
| 354 |
+
dim3 grid(num_tokens);
|
| 355 |
+
const int max_block_size = (num_tokens < 256) ? 1024 : 256;
|
| 356 |
+
dim3 block(std::min(d, max_block_size));
|
| 357 |
+
|
| 358 |
+
torch::Tensor temp_weight_grad =
|
| 359 |
+
torch::empty({num_tokens, d}, input.options().dtype(torch::kFloat));
|
| 360 |
+
|
| 361 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(input));
|
| 362 |
+
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 363 |
+
if (d % 8 == 0) {
|
| 364 |
+
LAUNCH_FUSED_ADD_RMS_NORM_BWD(8);
|
| 365 |
} else {
|
| 366 |
+
LAUNCH_FUSED_ADD_RMS_NORM_BWD(0);
|
| 367 |
+
}
|
| 368 |
+
|
| 369 |
+
if (weight_grad.defined()) {
|
| 370 |
+
torch::Tensor acc =
|
| 371 |
+
torch::empty_like(weight_grad, temp_weight_grad.options());
|
| 372 |
+
at::sum_out(acc, temp_weight_grad, {0});
|
| 373 |
+
weight_grad.copy_(acc);
|
| 374 |
}
|
| 375 |
}
|
activation/fused_mul_poly_norm.cu
CHANGED
|
@@ -573,7 +573,7 @@ void fused_mul_poly_norm(torch::Tensor &out, // [..., d]
|
|
| 573 |
}
|
| 574 |
}
|
| 575 |
|
| 576 |
-
#define
|
| 577 |
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 578 |
input.scalar_type(), "fused_mul_poly_norm_backward_kernel", [&] { \
|
| 579 |
motif::fused_mul_poly_norm_backward_kernel<scalar_t, float, width> \
|
|
@@ -620,11 +620,11 @@ void fused_mul_poly_norm_backward(torch::Tensor &input_grad, // [..., d]
|
|
| 620 |
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 621 |
|
| 622 |
if (d % 8 == 0 && input.element_size() == 2) {
|
| 623 |
-
|
| 624 |
} else if (d % 4 == 0 && input.element_size() == 4) {
|
| 625 |
-
|
| 626 |
} else {
|
| 627 |
-
|
| 628 |
}
|
| 629 |
|
| 630 |
if (bias_grad.defined()) {
|
|
|
|
| 573 |
}
|
| 574 |
}
|
| 575 |
|
| 576 |
+
#define LAUNCH_FUSED_MUL_POLY_NORM_BACKWARD(width) \
|
| 577 |
MOTIF_DISPATCH_FLOATING_TYPES( \
|
| 578 |
input.scalar_type(), "fused_mul_poly_norm_backward_kernel", [&] { \
|
| 579 |
motif::fused_mul_poly_norm_backward_kernel<scalar_t, float, width> \
|
|
|
|
| 620 |
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
|
| 621 |
|
| 622 |
if (d % 8 == 0 && input.element_size() == 2) {
|
| 623 |
+
LAUNCH_FUSED_MUL_POLY_NORM_BACKWARD(8);
|
| 624 |
} else if (d % 4 == 0 && input.element_size() == 4) {
|
| 625 |
+
LAUNCH_FUSED_MUL_POLY_NORM_BACKWARD(4);
|
| 626 |
} else {
|
| 627 |
+
LAUNCH_FUSED_MUL_POLY_NORM_BACKWARD(0);
|
| 628 |
}
|
| 629 |
|
| 630 |
if (bias_grad.defined()) {
|
benchmarks/cases/add_rms.py
CHANGED
|
@@ -12,7 +12,8 @@ class FusedAddRMSNorm(torch.nn.Module):
|
|
| 12 |
self.eps = eps
|
| 13 |
|
| 14 |
def forward(self, x, residual):
|
| 15 |
-
|
|
|
|
| 16 |
|
| 17 |
|
| 18 |
class AddRMS(DiffCase):
|
|
|
|
| 12 |
self.eps = eps
|
| 13 |
|
| 14 |
def forward(self, x, residual):
|
| 15 |
+
h = x + residual
|
| 16 |
+
return activation.rms_norm(h, self.weight, self.eps), h
|
| 17 |
|
| 18 |
|
| 19 |
class AddRMS(DiffCase):
|
benchmarks/common/bench_framework.py
CHANGED
|
@@ -149,7 +149,10 @@ def make_bwd_benchmark_for_case(
|
|
| 149 |
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 150 |
y = case.forward(obj, I)
|
| 151 |
gin = list(case.grad_inputs(I)) + list(obj.parameters())
|
| 152 |
-
|
|
|
|
|
|
|
|
|
|
| 153 |
run = lambda: torch.autograd.grad(y,
|
| 154 |
gin,
|
| 155 |
g,
|
|
@@ -201,7 +204,10 @@ def make_bwd_benchmark_plot_for_case(
|
|
| 201 |
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 202 |
y = case.forward(obj, I)
|
| 203 |
gin = list(case.grad_inputs(I)) + list(obj.parameters())
|
| 204 |
-
|
|
|
|
|
|
|
|
|
|
| 205 |
run = lambda: torch.autograd.grad(y,
|
| 206 |
gin,
|
| 207 |
g,
|
|
|
|
| 149 |
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 150 |
y = case.forward(obj, I)
|
| 151 |
gin = list(case.grad_inputs(I)) + list(obj.parameters())
|
| 152 |
+
if isinstance(y, torch.Tensor):
|
| 153 |
+
g = [torch.randn_like(y)]
|
| 154 |
+
else:
|
| 155 |
+
g = [torch.randn_like(r) for r in y]
|
| 156 |
run = lambda: torch.autograd.grad(y,
|
| 157 |
gin,
|
| 158 |
g,
|
|
|
|
| 204 |
obj = case.make_naive(I) if provider == "naive" else case.make_cuda(I)
|
| 205 |
y = case.forward(obj, I)
|
| 206 |
gin = list(case.grad_inputs(I)) + list(obj.parameters())
|
| 207 |
+
if isinstance(y, torch.Tensor):
|
| 208 |
+
g = [torch.randn_like(y)]
|
| 209 |
+
else:
|
| 210 |
+
g = [torch.randn_like(r) for r in y]
|
| 211 |
run = lambda: torch.autograd.grad(y,
|
| 212 |
gin,
|
| 213 |
g,
|
benchmarks/common/diff_engine.py
CHANGED
|
@@ -68,7 +68,10 @@ def calculate_diff(
|
|
| 68 |
torch.testing.assert_close(y_n, y_c, atol=atol, rtol=rtol)
|
| 69 |
gin_n = list(case.grad_inputs(I_n)) + list(obj_n.parameters())
|
| 70 |
gin_c = list(case.grad_inputs(I_c)) + list(obj_c.parameters())
|
| 71 |
-
|
|
|
|
|
|
|
|
|
|
| 72 |
ng = torch.autograd.grad(y_n,
|
| 73 |
gin_n,
|
| 74 |
g,
|
|
|
|
| 68 |
torch.testing.assert_close(y_n, y_c, atol=atol, rtol=rtol)
|
| 69 |
gin_n = list(case.grad_inputs(I_n)) + list(obj_n.parameters())
|
| 70 |
gin_c = list(case.grad_inputs(I_c)) + list(obj_c.parameters())
|
| 71 |
+
if isinstance(y_n, torch.Tensor):
|
| 72 |
+
g = [_unit_grad_like(y_n).to(device)]
|
| 73 |
+
else:
|
| 74 |
+
g = [_unit_grad_like(r).to(device) for r in y_n]
|
| 75 |
ng = torch.autograd.grad(y_n,
|
| 76 |
gin_n,
|
| 77 |
g,
|
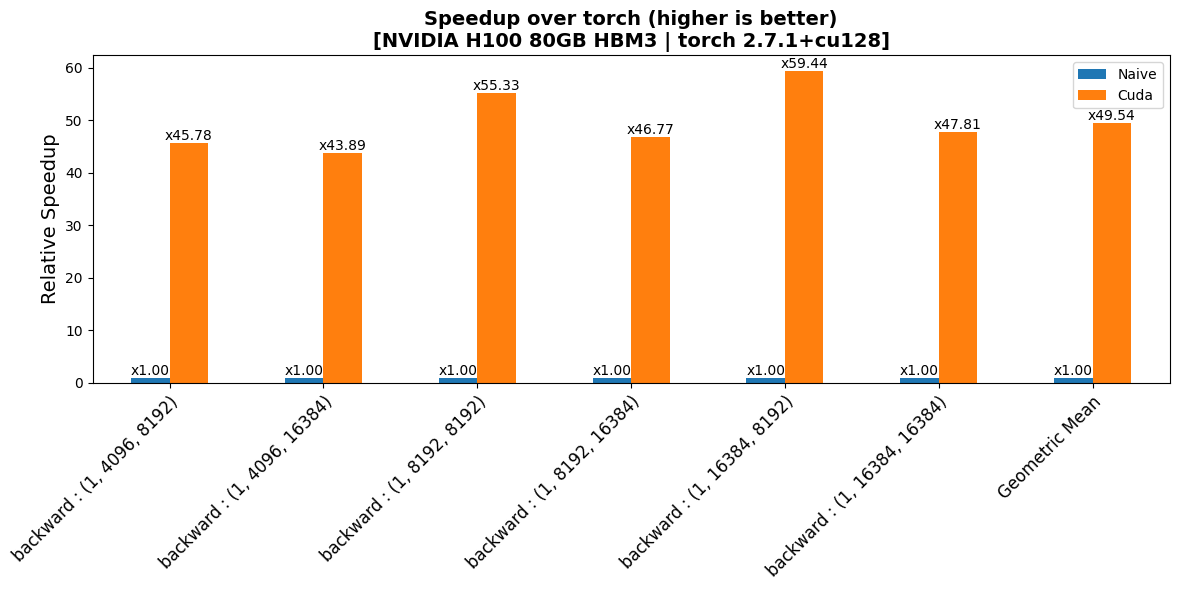
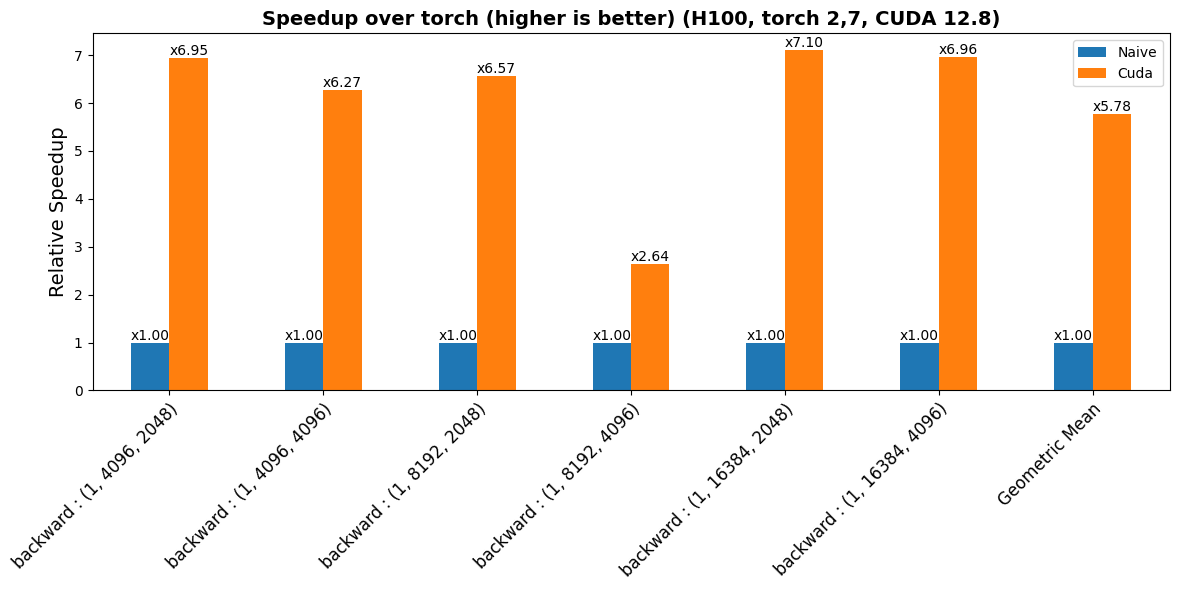
benchmarks/plots/h100/add_rms/plot_add_rms-bwd-perf.png
CHANGED
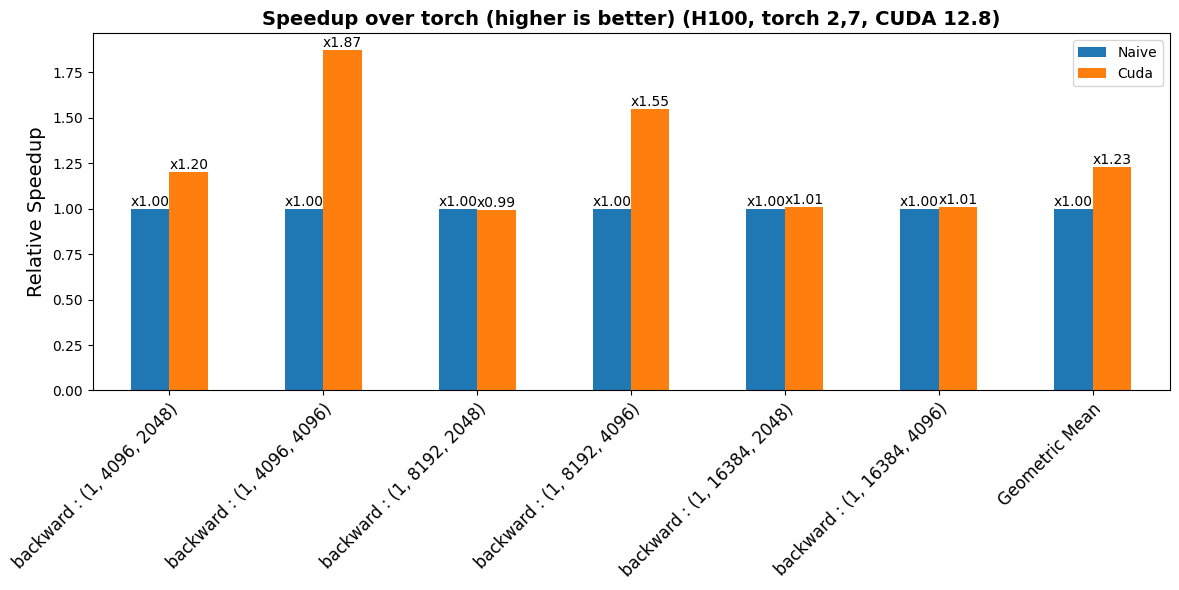
|

|
benchmarks/plots/h100/add_rms/plot_add_rms-fwd-perf.png
CHANGED

|

|
benchmarks/plots/h100/mul_poly/plot_mul_poly-bwd-perf.png
CHANGED

|
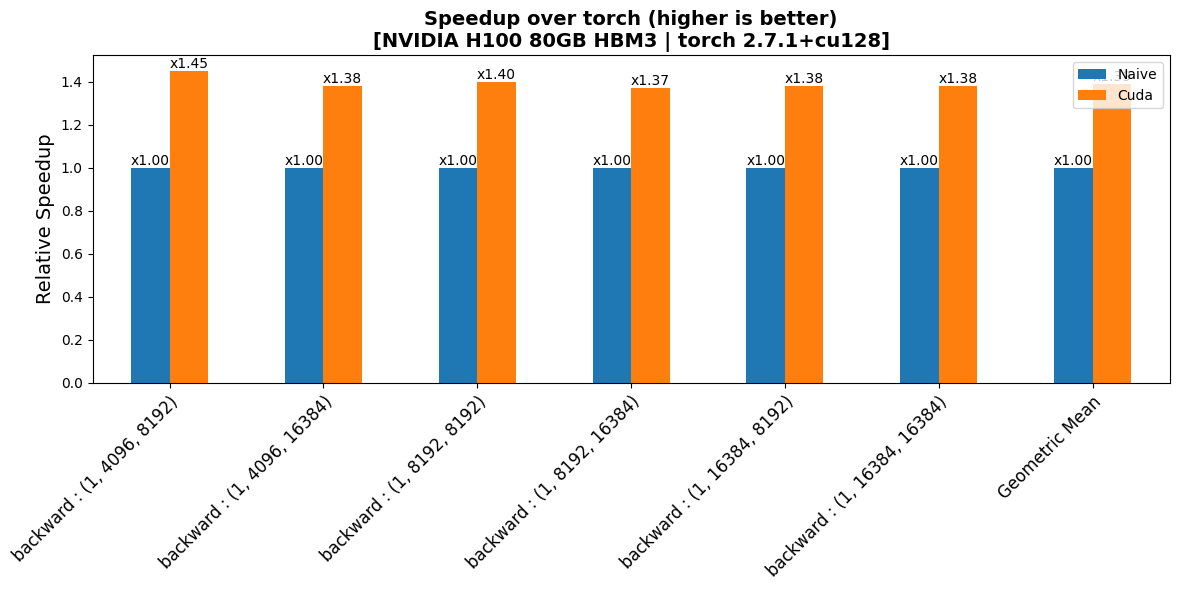
|
benchmarks/plots/h100/mul_poly/plot_mul_poly-fwd-perf.png
CHANGED

|
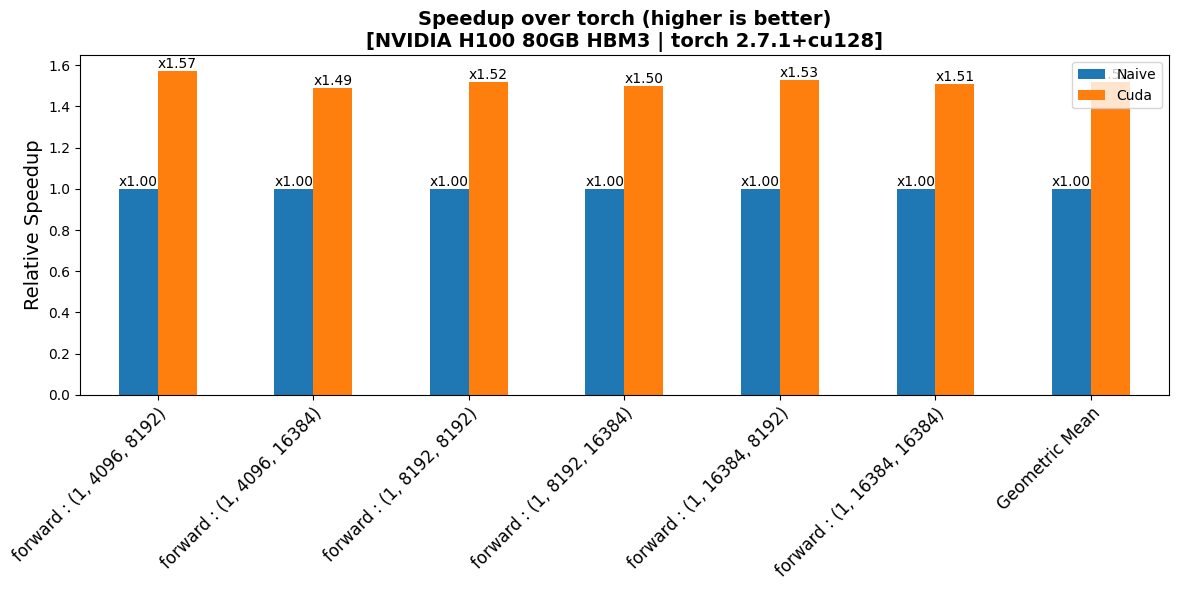
|
benchmarks/plots/h100/poly/plot_poly-bwd-perf.png
CHANGED

|
|
benchmarks/plots/h100/poly/plot_poly-fwd-perf.png
CHANGED
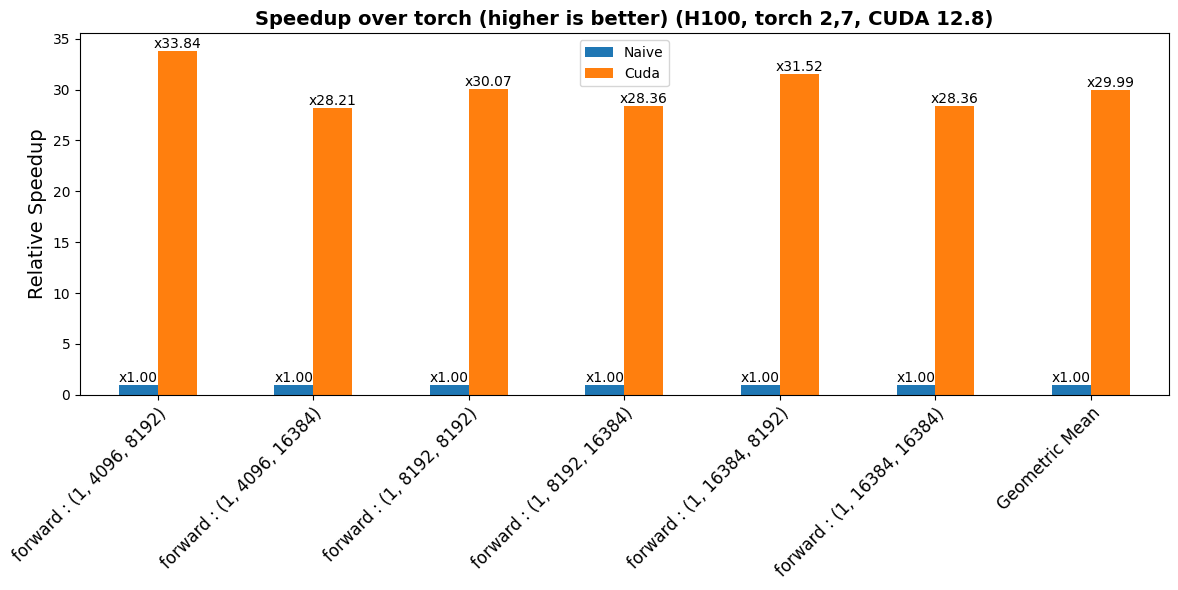
|
|
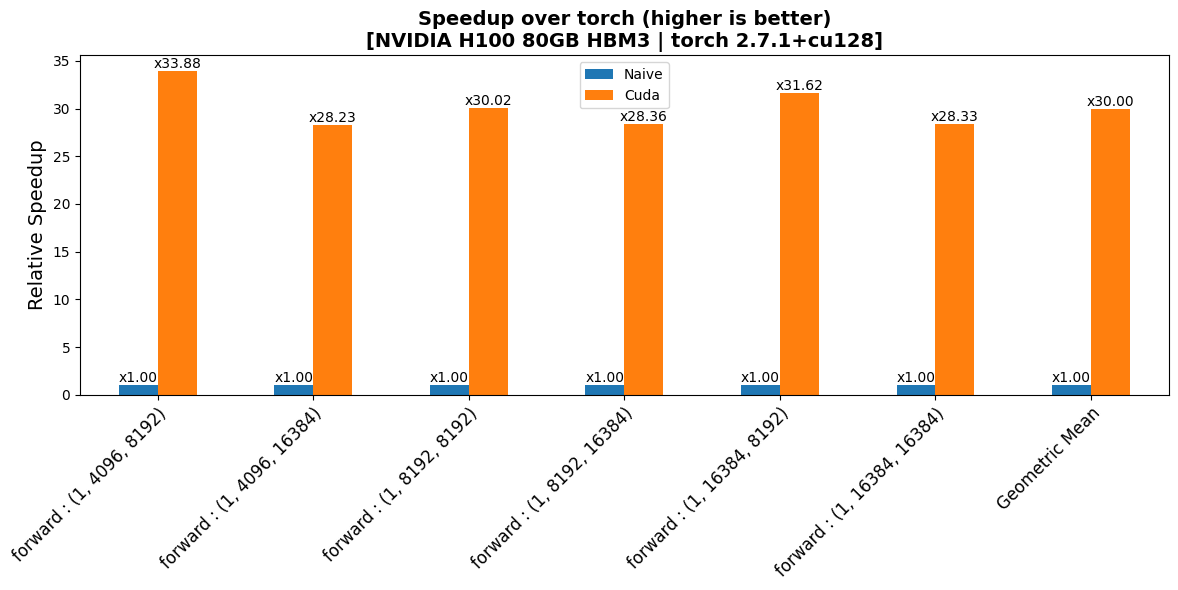
benchmarks/plots/h100/rms/plot_rms-bwd-perf.png
CHANGED
|

|
benchmarks/plots/h100/rms/plot_rms-fwd-perf.png
CHANGED

|

|
benchmarks/plots/mi250/add_rms/plot_add_rms-bwd-perf.png
CHANGED
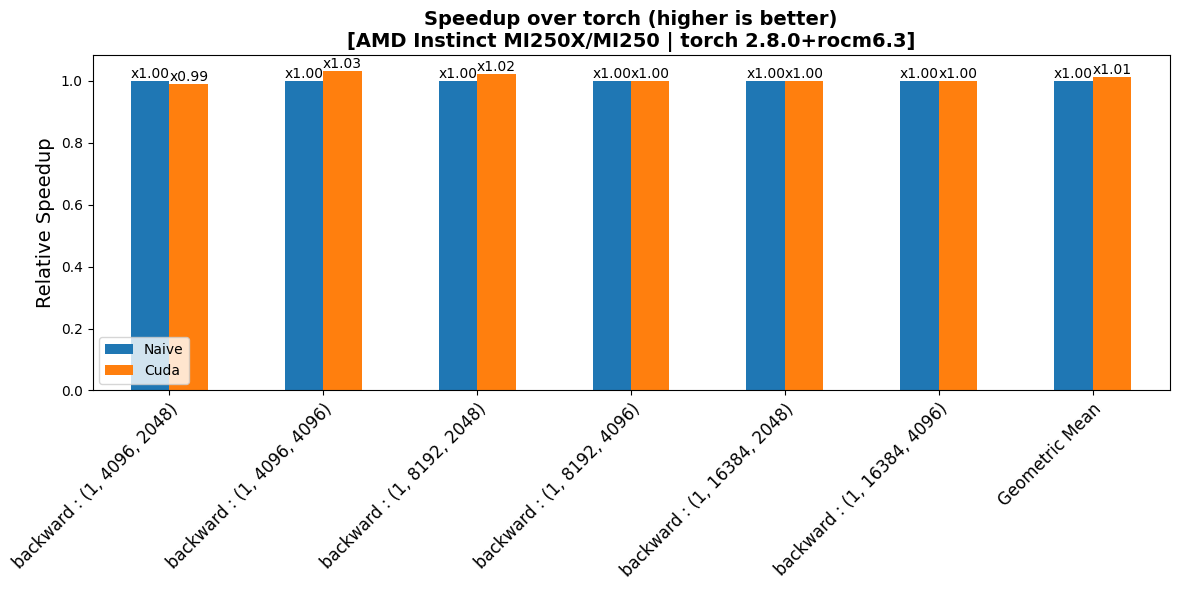
|

|
benchmarks/plots/mi250/add_rms/plot_add_rms-fwd-perf.png
CHANGED

|

|
build/torch27-cxx11-cu118-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -39,7 +39,7 @@ def fused_add_rms_norm(
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
-
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
|
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
build/torch27-cxx11-cu118-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec9ea7edc8b27f7983e20d615ab470cef6b82975afc214becfddfd05a867a839
|
| 3 |
+
size 8600336
|
build/torch27-cxx11-cu118-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_e5e2eeb_dirty
|
| 3 |
+
ops = torch.ops._activation_e5e2eeb_dirty
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_e5e2eeb_dirty::{op_name}"
|
build/torch27-cxx11-cu118-x86_64-linux/activation/layers.py
CHANGED
|
@@ -85,7 +85,7 @@ class FusedAddRMSNorm(nn.Module):
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
-
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
|
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
build/torch27-cxx11-cu118-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -54,20 +54,14 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
| 57 |
-
ctx.mark_non_differentiable(add_output)
|
| 58 |
-
ctx.set_materialize_grads(False)
|
| 59 |
ctx.save_for_backward(weight, add_output)
|
| 60 |
ctx.eps = eps
|
| 61 |
|
| 62 |
-
# This function only needs one gradient
|
| 63 |
@staticmethod
|
| 64 |
-
def backward(ctx, output_grad,
|
| 65 |
weight, add_output = ctx.saved_tensors
|
| 66 |
eps = ctx.eps
|
| 67 |
|
| 68 |
-
if output_grad is None:
|
| 69 |
-
output_grad = torch.zeros_like(add_output)
|
| 70 |
-
|
| 71 |
need_in = ctx.needs_input_grad[0]
|
| 72 |
need_res = ctx.needs_input_grad[1]
|
| 73 |
|
|
@@ -76,7 +70,7 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 76 |
weight_grad = torch.empty_like(
|
| 77 |
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
|
| 79 |
-
ops.
|
| 80 |
weight, eps)
|
| 81 |
input_grad = grad if need_in else None
|
| 82 |
residual_grad = grad if need_res else None
|
|
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
|
|
|
|
|
|
| 57 |
ctx.save_for_backward(weight, add_output)
|
| 58 |
ctx.eps = eps
|
| 59 |
|
|
|
|
| 60 |
@staticmethod
|
| 61 |
+
def backward(ctx, output_grad, add_output_grad):
|
| 62 |
weight, add_output = ctx.saved_tensors
|
| 63 |
eps = ctx.eps
|
| 64 |
|
|
|
|
|
|
|
|
|
|
| 65 |
need_in = ctx.needs_input_grad[0]
|
| 66 |
need_res = ctx.needs_input_grad[1]
|
| 67 |
|
|
|
|
| 70 |
weight_grad = torch.empty_like(
|
| 71 |
weight) if ctx.needs_input_grad[2] else None
|
| 72 |
|
| 73 |
+
ops.fused_add_rms_norm_backward(grad, weight_grad, output_grad, add_output_grad, add_output,
|
| 74 |
weight, eps)
|
| 75 |
input_grad = grad if need_in else None
|
| 76 |
residual_grad = grad if need_res else None
|
build/torch27-cxx11-cu126-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -39,7 +39,7 @@ def fused_add_rms_norm(
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
-
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
|
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
build/torch27-cxx11-cu126-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d3511410cdc288d2fafc500223ed2e625e360f50fa341809cf892fb2c822924
|
| 3 |
+
size 8779000
|
build/torch27-cxx11-cu126-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_e5e2eeb_dirty
|
| 3 |
+
ops = torch.ops._activation_e5e2eeb_dirty
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_e5e2eeb_dirty::{op_name}"
|
build/torch27-cxx11-cu126-x86_64-linux/activation/layers.py
CHANGED
|
@@ -85,7 +85,7 @@ class FusedAddRMSNorm(nn.Module):
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
-
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
|
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
build/torch27-cxx11-cu126-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -54,20 +54,14 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
| 57 |
-
ctx.mark_non_differentiable(add_output)
|
| 58 |
-
ctx.set_materialize_grads(False)
|
| 59 |
ctx.save_for_backward(weight, add_output)
|
| 60 |
ctx.eps = eps
|
| 61 |
|
| 62 |
-
# This function only needs one gradient
|
| 63 |
@staticmethod
|
| 64 |
-
def backward(ctx, output_grad,
|
| 65 |
weight, add_output = ctx.saved_tensors
|
| 66 |
eps = ctx.eps
|
| 67 |
|
| 68 |
-
if output_grad is None:
|
| 69 |
-
output_grad = torch.zeros_like(add_output)
|
| 70 |
-
|
| 71 |
need_in = ctx.needs_input_grad[0]
|
| 72 |
need_res = ctx.needs_input_grad[1]
|
| 73 |
|
|
@@ -76,7 +70,7 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 76 |
weight_grad = torch.empty_like(
|
| 77 |
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
|
| 79 |
-
ops.
|
| 80 |
weight, eps)
|
| 81 |
input_grad = grad if need_in else None
|
| 82 |
residual_grad = grad if need_res else None
|
|
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
|
|
|
|
|
|
| 57 |
ctx.save_for_backward(weight, add_output)
|
| 58 |
ctx.eps = eps
|
| 59 |
|
|
|
|
| 60 |
@staticmethod
|
| 61 |
+
def backward(ctx, output_grad, add_output_grad):
|
| 62 |
weight, add_output = ctx.saved_tensors
|
| 63 |
eps = ctx.eps
|
| 64 |
|
|
|
|
|
|
|
|
|
|
| 65 |
need_in = ctx.needs_input_grad[0]
|
| 66 |
need_res = ctx.needs_input_grad[1]
|
| 67 |
|
|
|
|
| 70 |
weight_grad = torch.empty_like(
|
| 71 |
weight) if ctx.needs_input_grad[2] else None
|
| 72 |
|
| 73 |
+
ops.fused_add_rms_norm_backward(grad, weight_grad, output_grad, add_output_grad, add_output,
|
| 74 |
weight, eps)
|
| 75 |
input_grad = grad if need_in else None
|
| 76 |
residual_grad = grad if need_res else None
|
build/torch27-cxx11-cu128-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -39,7 +39,7 @@ def fused_add_rms_norm(
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
-
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
|
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
build/torch27-cxx11-cu128-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:25efc9c32e4bd6609a8326025aad861cbf79b544893755fe44519c9df7224c40
|
| 3 |
+
size 13818872
|
build/torch27-cxx11-cu128-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_e5e2eeb_dirty
|
| 3 |
+
ops = torch.ops._activation_e5e2eeb_dirty
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_e5e2eeb_dirty::{op_name}"
|
build/torch27-cxx11-cu128-x86_64-linux/activation/layers.py
CHANGED
|
@@ -85,7 +85,7 @@ class FusedAddRMSNorm(nn.Module):
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
-
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
|
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
build/torch27-cxx11-cu128-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -54,20 +54,14 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
| 57 |
-
ctx.mark_non_differentiable(add_output)
|
| 58 |
-
ctx.set_materialize_grads(False)
|
| 59 |
ctx.save_for_backward(weight, add_output)
|
| 60 |
ctx.eps = eps
|
| 61 |
|
| 62 |
-
# This function only needs one gradient
|
| 63 |
@staticmethod
|
| 64 |
-
def backward(ctx, output_grad,
|
| 65 |
weight, add_output = ctx.saved_tensors
|
| 66 |
eps = ctx.eps
|
| 67 |
|
| 68 |
-
if output_grad is None:
|
| 69 |
-
output_grad = torch.zeros_like(add_output)
|
| 70 |
-
|
| 71 |
need_in = ctx.needs_input_grad[0]
|
| 72 |
need_res = ctx.needs_input_grad[1]
|
| 73 |
|
|
@@ -76,7 +70,7 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 76 |
weight_grad = torch.empty_like(
|
| 77 |
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
|
| 79 |
-
ops.
|
| 80 |
weight, eps)
|
| 81 |
input_grad = grad if need_in else None
|
| 82 |
residual_grad = grad if need_res else None
|
|
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
|
|
|
|
|
|
| 57 |
ctx.save_for_backward(weight, add_output)
|
| 58 |
ctx.eps = eps
|
| 59 |
|
|
|
|
| 60 |
@staticmethod
|
| 61 |
+
def backward(ctx, output_grad, add_output_grad):
|
| 62 |
weight, add_output = ctx.saved_tensors
|
| 63 |
eps = ctx.eps
|
| 64 |
|
|
|
|
|
|
|
|
|
|
| 65 |
need_in = ctx.needs_input_grad[0]
|
| 66 |
need_res = ctx.needs_input_grad[1]
|
| 67 |
|
|
|
|
| 70 |
weight_grad = torch.empty_like(
|
| 71 |
weight) if ctx.needs_input_grad[2] else None
|
| 72 |
|
| 73 |
+
ops.fused_add_rms_norm_backward(grad, weight_grad, output_grad, add_output_grad, add_output,
|
| 74 |
weight, eps)
|
| 75 |
input_grad = grad if need_in else None
|
| 76 |
residual_grad = grad if need_res else None
|
build/torch27-cxx11-rocm63-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -39,7 +39,7 @@ def fused_add_rms_norm(
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
-
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
|
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
build/torch27-cxx11-rocm63-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c80d05690547f2842d416ebb85c9f830370373bc7e6c54ba08eec61b3690280f
|
| 3 |
+
size 4386744
|
build/torch27-cxx11-rocm63-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_e5e2eeb_dirty
|
| 3 |
+
ops = torch.ops._activation_e5e2eeb_dirty
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_e5e2eeb_dirty::{op_name}"
|
build/torch27-cxx11-rocm63-x86_64-linux/activation/layers.py
CHANGED
|
@@ -85,7 +85,7 @@ class FusedAddRMSNorm(nn.Module):
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
-
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
|
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
build/torch27-cxx11-rocm63-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -54,20 +54,14 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
| 57 |
-
ctx.mark_non_differentiable(add_output)
|
| 58 |
-
ctx.set_materialize_grads(False)
|
| 59 |
ctx.save_for_backward(weight, add_output)
|
| 60 |
ctx.eps = eps
|
| 61 |
|
| 62 |
-
# This function only needs one gradient
|
| 63 |
@staticmethod
|
| 64 |
-
def backward(ctx, output_grad,
|
| 65 |
weight, add_output = ctx.saved_tensors
|
| 66 |
eps = ctx.eps
|
| 67 |
|
| 68 |
-
if output_grad is None:
|
| 69 |
-
output_grad = torch.zeros_like(add_output)
|
| 70 |
-
|
| 71 |
need_in = ctx.needs_input_grad[0]
|
| 72 |
need_res = ctx.needs_input_grad[1]
|
| 73 |
|
|
@@ -76,7 +70,7 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 76 |
weight_grad = torch.empty_like(
|
| 77 |
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
|
| 79 |
-
ops.
|
| 80 |
weight, eps)
|
| 81 |
input_grad = grad if need_in else None
|
| 82 |
residual_grad = grad if need_res else None
|
|
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
|
|
|
|
|
|
| 57 |
ctx.save_for_backward(weight, add_output)
|
| 58 |
ctx.eps = eps
|
| 59 |
|
|
|
|
| 60 |
@staticmethod
|
| 61 |
+
def backward(ctx, output_grad, add_output_grad):
|
| 62 |
weight, add_output = ctx.saved_tensors
|
| 63 |
eps = ctx.eps
|
| 64 |
|
|
|
|
|
|
|
|
|
|
| 65 |
need_in = ctx.needs_input_grad[0]
|
| 66 |
need_res = ctx.needs_input_grad[1]
|
| 67 |
|
|
|
|
| 70 |
weight_grad = torch.empty_like(
|
| 71 |
weight) if ctx.needs_input_grad[2] else None
|
| 72 |
|
| 73 |
+
ops.fused_add_rms_norm_backward(grad, weight_grad, output_grad, add_output_grad, add_output,
|
| 74 |
weight, eps)
|
| 75 |
input_grad = grad if need_in else None
|
| 76 |
residual_grad = grad if need_res else None
|
build/torch28-cxx11-cu126-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -39,7 +39,7 @@ def fused_add_rms_norm(
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
-
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
|
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
build/torch28-cxx11-cu126-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:440f5c17a7ddaf73c506bbc84fd1405e2e188b8ceaf4977910608be6b91e89bf
|
| 3 |
+
size 8730200
|
build/torch28-cxx11-cu126-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_e5e2eeb_dirty
|
| 3 |
+
ops = torch.ops._activation_e5e2eeb_dirty
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_e5e2eeb_dirty::{op_name}"
|
build/torch28-cxx11-cu126-x86_64-linux/activation/layers.py
CHANGED
|
@@ -85,7 +85,7 @@ class FusedAddRMSNorm(nn.Module):
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
-
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
|
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
build/torch28-cxx11-cu126-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -54,20 +54,14 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
| 57 |
-
ctx.mark_non_differentiable(add_output)
|
| 58 |
-
ctx.set_materialize_grads(False)
|
| 59 |
ctx.save_for_backward(weight, add_output)
|
| 60 |
ctx.eps = eps
|
| 61 |
|
| 62 |
-
# This function only needs one gradient
|
| 63 |
@staticmethod
|
| 64 |
-
def backward(ctx, output_grad,
|
| 65 |
weight, add_output = ctx.saved_tensors
|
| 66 |
eps = ctx.eps
|
| 67 |
|
| 68 |
-
if output_grad is None:
|
| 69 |
-
output_grad = torch.zeros_like(add_output)
|
| 70 |
-
|
| 71 |
need_in = ctx.needs_input_grad[0]
|
| 72 |
need_res = ctx.needs_input_grad[1]
|
| 73 |
|
|
@@ -76,7 +70,7 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 76 |
weight_grad = torch.empty_like(
|
| 77 |
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
|
| 79 |
-
ops.
|
| 80 |
weight, eps)
|
| 81 |
input_grad = grad if need_in else None
|
| 82 |
residual_grad = grad if need_res else None
|
|
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
|
|
|
|
|
|
| 57 |
ctx.save_for_backward(weight, add_output)
|
| 58 |
ctx.eps = eps
|
| 59 |
|
|
|
|
| 60 |
@staticmethod
|
| 61 |
+
def backward(ctx, output_grad, add_output_grad):
|
| 62 |
weight, add_output = ctx.saved_tensors
|
| 63 |
eps = ctx.eps
|
| 64 |
|
|
|
|
|
|
|
|
|
|
| 65 |
need_in = ctx.needs_input_grad[0]
|
| 66 |
need_res = ctx.needs_input_grad[1]
|
| 67 |
|
|
|
|
| 70 |
weight_grad = torch.empty_like(
|
| 71 |
weight) if ctx.needs_input_grad[2] else None
|
| 72 |
|
| 73 |
+
ops.fused_add_rms_norm_backward(grad, weight_grad, output_grad, add_output_grad, add_output,
|
| 74 |
weight, eps)
|
| 75 |
input_grad = grad if need_in else None
|
| 76 |
residual_grad = grad if need_res else None
|
build/torch28-cxx11-cu128-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -39,7 +39,7 @@ def fused_add_rms_norm(
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
-
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
|
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
build/torch28-cxx11-cu128-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1dfb6d468f9cef0239d4ea47f0a247fa721befc5b8db86e1cddfc25f1814b67a
|
| 3 |
+
size 13770064
|
build/torch28-cxx11-cu128-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_e5e2eeb_dirty
|
| 3 |
+
ops = torch.ops._activation_e5e2eeb_dirty
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_e5e2eeb_dirty::{op_name}"
|
build/torch28-cxx11-cu128-x86_64-linux/activation/layers.py
CHANGED
|
@@ -85,7 +85,7 @@ class FusedAddRMSNorm(nn.Module):
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
-
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
|
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
build/torch28-cxx11-cu128-x86_64-linux/activation/rms_norm.py
CHANGED
|
@@ -54,20 +54,14 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
| 57 |
-
ctx.mark_non_differentiable(add_output)
|
| 58 |
-
ctx.set_materialize_grads(False)
|
| 59 |
ctx.save_for_backward(weight, add_output)
|
| 60 |
ctx.eps = eps
|
| 61 |
|
| 62 |
-
# This function only needs one gradient
|
| 63 |
@staticmethod
|
| 64 |
-
def backward(ctx, output_grad,
|
| 65 |
weight, add_output = ctx.saved_tensors
|
| 66 |
eps = ctx.eps
|
| 67 |
|
| 68 |
-
if output_grad is None:
|
| 69 |
-
output_grad = torch.zeros_like(add_output)
|
| 70 |
-
|
| 71 |
need_in = ctx.needs_input_grad[0]
|
| 72 |
need_res = ctx.needs_input_grad[1]
|
| 73 |
|
|
@@ -76,7 +70,7 @@ class FusedAddRMSNormFunction(torch.autograd.Function):
|
|
| 76 |
weight_grad = torch.empty_like(
|
| 77 |
weight) if ctx.needs_input_grad[2] else None
|
| 78 |
|
| 79 |
-
ops.
|
| 80 |
weight, eps)
|
| 81 |
input_grad = grad if need_in else None
|
| 82 |
residual_grad = grad if need_res else None
|
|
|
|
| 54 |
def setup_context(ctx, inputs, outputs):
|
| 55 |
_, _, weight, eps = inputs
|
| 56 |
_, add_output = outputs
|
|
|
|
|
|
|
| 57 |
ctx.save_for_backward(weight, add_output)
|
| 58 |
ctx.eps = eps
|
| 59 |
|
|
|
|
| 60 |
@staticmethod
|
| 61 |
+
def backward(ctx, output_grad, add_output_grad):
|
| 62 |
weight, add_output = ctx.saved_tensors
|
| 63 |
eps = ctx.eps
|
| 64 |
|
|
|
|
|
|
|
|
|
|
| 65 |
need_in = ctx.needs_input_grad[0]
|
| 66 |
need_res = ctx.needs_input_grad[1]
|
| 67 |
|
|
|
|
| 70 |
weight_grad = torch.empty_like(
|
| 71 |
weight) if ctx.needs_input_grad[2] else None
|
| 72 |
|
| 73 |
+
ops.fused_add_rms_norm_backward(grad, weight_grad, output_grad, add_output_grad, add_output,
|
| 74 |
weight, eps)
|
| 75 |
input_grad = grad if need_in else None
|
| 76 |
residual_grad = grad if need_res else None
|
build/torch28-cxx11-cu129-x86_64-linux/activation/__init__.py
CHANGED
|
@@ -39,7 +39,7 @@ def fused_add_rms_norm(
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
-
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
|
|
|
| 39 |
weight: torch.Tensor,
|
| 40 |
eps: float = 1e-6,
|
| 41 |
) -> None:
|
| 42 |
+
return FusedAddRMSNormFunction.apply(x, residual, weight, eps)
|
| 43 |
|
| 44 |
|
| 45 |
__all__ = [
|
build/torch28-cxx11-cu129-x86_64-linux/activation/_activation_e5e2eeb_dirty.abi3.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0815a50e61497b357b2b90fc28602b3f53a25da1161edd2cb0b0fbebc7c62bf6
|
| 3 |
+
size 13757248
|
build/torch28-cxx11-cu129-x86_64-linux/activation/_ops.py
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
import torch
|
| 2 |
-
from . import
|
| 3 |
-
ops = torch.ops.
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
-
return f"
|
|
|
|
| 1 |
import torch
|
| 2 |
+
from . import _activation_e5e2eeb_dirty
|
| 3 |
+
ops = torch.ops._activation_e5e2eeb_dirty
|
| 4 |
|
| 5 |
def add_op_namespace_prefix(op_name: str):
|
| 6 |
"""
|
| 7 |
Prefix op by namespace.
|
| 8 |
"""
|
| 9 |
+
return f"_activation_e5e2eeb_dirty::{op_name}"
|
build/torch28-cxx11-cu129-x86_64-linux/activation/layers.py
CHANGED
|
@@ -85,7 +85,7 @@ class FusedAddRMSNorm(nn.Module):
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
-
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|
|
|
|
| 85 |
residual: torch.Tensor,
|
| 86 |
):
|
| 87 |
return FusedAddRMSNormFunction.apply(x, residual, self.weight,
|
| 88 |
+
self.eps)
|
| 89 |
|
| 90 |
def reset_parameters(self) -> None:
|
| 91 |
"""
|