
shuai bai
commited on
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,136 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
|
| 5 |
+
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
| 6 |
+
</a>
|
| 7 |
+
|
| 8 |
+
## Introduction
|
| 9 |
+
The goal of Qwen3-VL is not just to “see” images or videos — but to truly understand the world, interpret events, and take action. To achieve this, we’ve systematically upgraded key capabilities, pushing visual models from simple “perception” toward deeper “cognition,” and from basic “recognition” to advanced “reasoning and execution.”
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
**Key Highlights:**
|
| 14 |
+
|
| 15 |
+
- **Visual Agent Capabilities**: Qwen3-VL can operate computer and mobile interfaces — recognize GUI elements, understand button functions, call tools, and complete tasks. It achieves top global performance on benchmarks like OS World, and using tools significantly improves its performance on fine-grained perception tasks.
|
| 16 |
+
|
| 17 |
+
- **Greatly Improved Visual Coding**: It can now generate code from images or videos — for example, turning a design mockup into Draw.io, HTML, CSS, or JavaScript code — making “what you see is what you get” visual programming a reality.
|
| 18 |
+
|
| 19 |
+
- **Much Better Spatial Understanding**: 2D grounding is strengthened and the coordinate is transformed from absolute to relative, enabling more robust estimation of object locations, viewpoint (camera pose) changes, and occlusion structure. The model also supports 3D grounding, providing a foundation for complex spatial reasoning and embodied AI applications.
|
| 20 |
+
|
| 21 |
+
- **Long Context & Long Video Understanding**: Natively support 256K tokens of context, expandable up to 1 million tokens. This means you can input hundreds of pages of technical documentation, entire textbooks, and even two‑hour recordings of meetings or lectures — and achieves reliable long‑context retention and precise retrieval, including second‑level timestamp localization in video.
|
| 22 |
+
|
| 23 |
+
- **Stronger Multimodal Reasoning (Thinking Version)**: The Thinking model is optimized for STEM reasoning. On complex problems, it attends to fine‑grained cues, performs step‑by‑step decomposition, analyzes causal dependencies, and produces logically consistent, evidence‑grounded solutions. It achieves state‑of‑the‑art results on benchmarks including MathVision, MMMU, and MathVista.
|
| 24 |
+
|
| 25 |
+
- **Upgraded Visual Perception & Recognition**: Improvements to the quality and diversity of the pretraining corpus have expanded the model’s recognition ability to a broader range of objects and entities, including celebrities, anime characters, consumer products, landmarks, and flora/fauna, — covering both everyday life and professional “recognize anything” needs.
|
| 26 |
+
|
| 27 |
+
- **Better OCR Across More Languages & Complex Scenes**: OCR now supports 32 languages (up from 19), covering more countries and regions. It demonstrates greater robustness under challenging real-world conditions like poor lighting, blur, or tilted text. Recognition accuracy for rare characters, ancient scripts, and technical terms has also improved significantly. Its ability to understand long documents and reconstruct fine structures is further enhanced.
|
| 28 |
+
|
| 29 |
+
This is the weight repository for Qwen3-VL-235B-A22B-Instruct.
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
---
|
| 33 |
+
|
| 34 |
+
## Model Performance
|
| 35 |
+
|
| 36 |
+
**Multimodal performance**
|
| 37 |
+
|
| 38 |
+
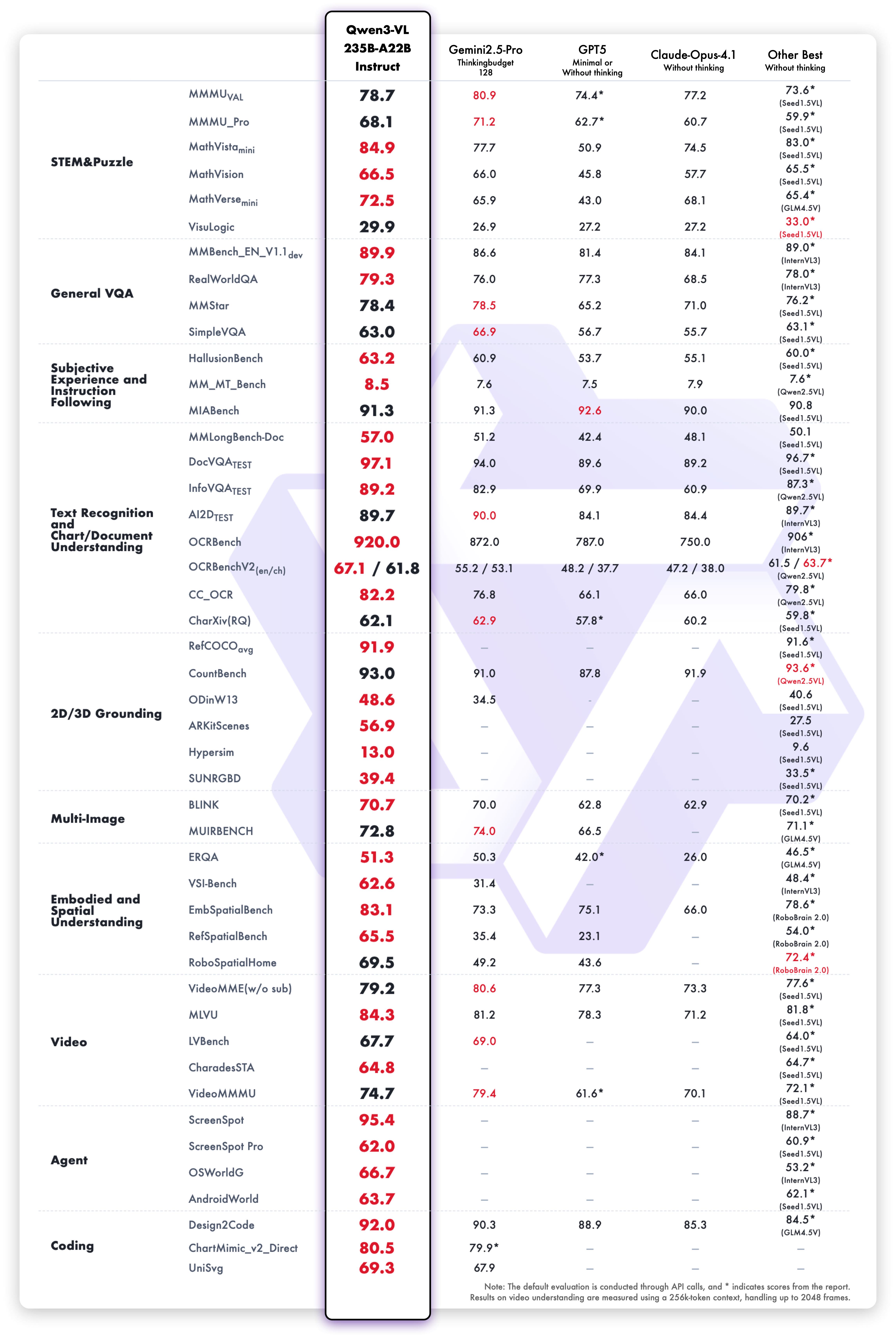
|
| 39 |
+
|
| 40 |
+
**Pure text performance**
|
| 41 |
+
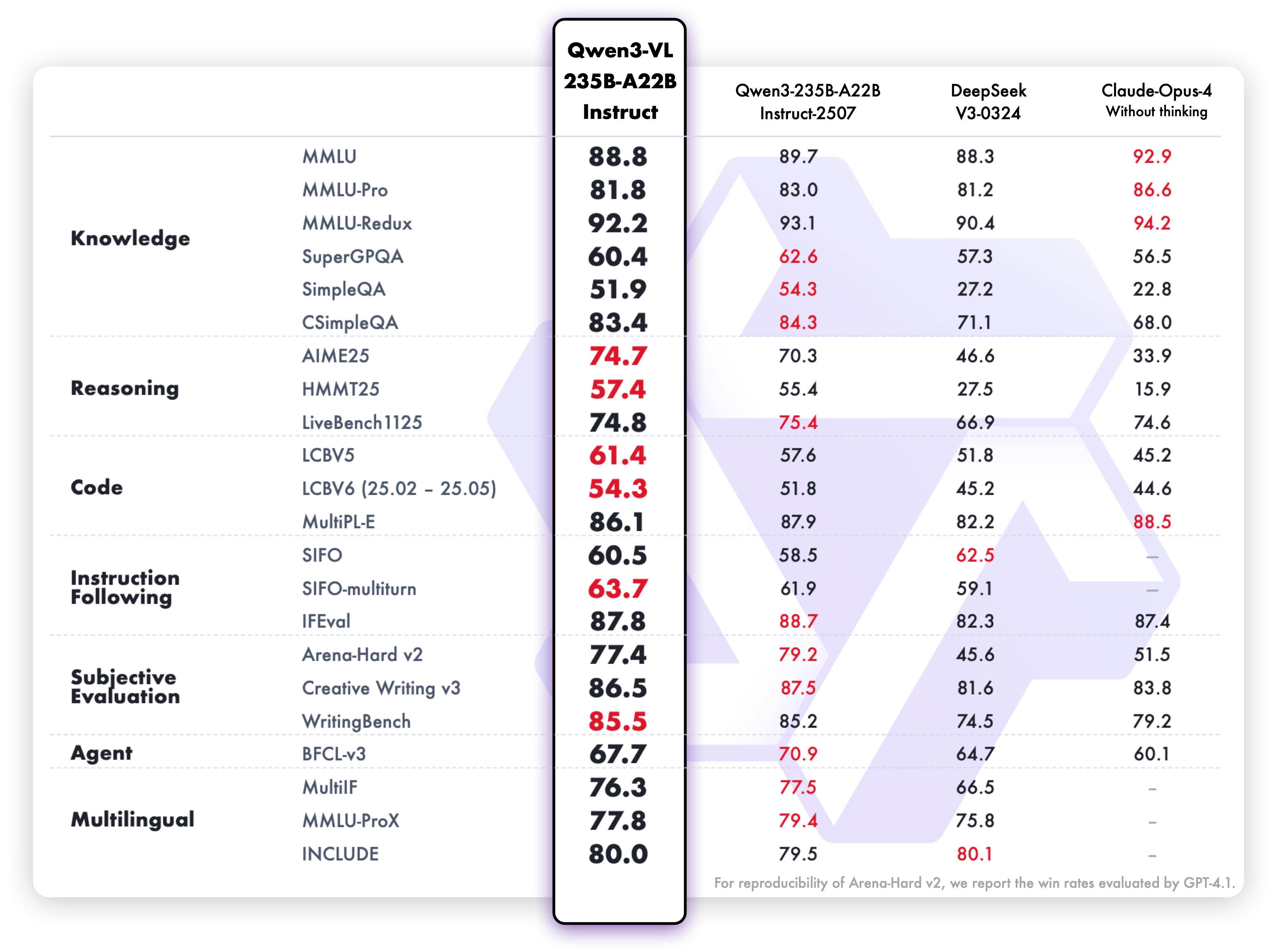
|
| 42 |
+
|
| 43 |
+
## Quickstart
|
| 44 |
+
|
| 45 |
+
Below, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.
|
| 46 |
+
|
| 47 |
+
The code of Qwen3-VL has been in the latest Hugging Face transformers and we advise you to build from source with command:
|
| 48 |
+
```
|
| 49 |
+
pip install git+https://github.com/huggingface/transformers
|
| 50 |
+
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
### Using 🤗 Transformers to Chat
|
| 54 |
+
|
| 55 |
+
Here we show a code snippet to show how to use the chat model with `transformers`:
|
| 56 |
+
|
| 57 |
+
```python
|
| 58 |
+
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor
|
| 59 |
+
|
| 60 |
+
# default: Load the model on the available device(s)
|
| 61 |
+
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
|
| 62 |
+
"Qwen/Qwen3-VL-235B-A22B-Instruct", dtype="auto", device_map="auto"
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
|
| 66 |
+
# model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
|
| 67 |
+
# "Qwen/Qwen3-VL-235B-A22B-Instruct",
|
| 68 |
+
# dtype=torch.bfloat16,
|
| 69 |
+
# attn_implementation="flash_attention_2",
|
| 70 |
+
# device_map="auto",
|
| 71 |
+
# )
|
| 72 |
+
|
| 73 |
+
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
|
| 74 |
+
|
| 75 |
+
messages = [
|
| 76 |
+
{
|
| 77 |
+
"role": "user",
|
| 78 |
+
"content": [
|
| 79 |
+
{
|
| 80 |
+
"type": "image",
|
| 81 |
+
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
|
| 82 |
+
},
|
| 83 |
+
{"type": "text", "text": "Describe this image."},
|
| 84 |
+
],
|
| 85 |
+
}
|
| 86 |
+
]
|
| 87 |
+
|
| 88 |
+
# Preparation for inference
|
| 89 |
+
inputs = processor.apply_chat_template(
|
| 90 |
+
messages,
|
| 91 |
+
tokenize=True,
|
| 92 |
+
add_generation_prompt=True,
|
| 93 |
+
return_dict=True,
|
| 94 |
+
return_tensors="pt"
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
# Inference: Generation of the output
|
| 98 |
+
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
| 99 |
+
generated_ids_trimmed = [
|
| 100 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 101 |
+
]
|
| 102 |
+
output_text = processor.batch_decode(
|
| 103 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 104 |
+
)
|
| 105 |
+
print(output_text)
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
## Citation
|
| 111 |
+
|
| 112 |
+
If you find our work helpful, feel free to give us a cite.
|
| 113 |
+
|
| 114 |
+
```
|
| 115 |
+
@misc{qwen2.5-VL,
|
| 116 |
+
title = {Qwen2.5-VL},
|
| 117 |
+
url = {https://qwenlm.github.io/blog/qwen2.5-vl/},
|
| 118 |
+
author = {Qwen Team},
|
| 119 |
+
month = {January},
|
| 120 |
+
year = {2025}
|
| 121 |
+
}
|
| 122 |
+
|
| 123 |
+
@article{Qwen2VL,
|
| 124 |
+
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
|
| 125 |
+
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
|
| 126 |
+
journal={arXiv preprint arXiv:2409.12191},
|
| 127 |
+
year={2024}
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
@article{Qwen-VL,
|
| 131 |
+
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
|
| 132 |
+
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
|
| 133 |
+
journal={arXiv preprint arXiv:2308.12966},
|
| 134 |
+
year={2023}
|
| 135 |
+
}
|
| 136 |
+
```
|