Hugging Face
Models
Datasets
Spaces
Community
Docs
Enterprise
Pricing
Log In
Sign Up
Blog, Articles, and discussions
New Article
community
guide
open source collab
partnerships
research
NLP
Audio
CV
RL
ethics
Diffusion
Game Development
RLHF
Leaderboard
Case Studies
LeRobot
Inference Providers
Community Articles
view all
We’re open-sourcing our text-to-image model and the process behind it
9 days ago
•
65
Text-to-image Architectural Experiments
7 days ago
•
32
Introducing Cogito v2.1
1 day ago
•
16
Apriel-H1: The Surprising Key to Distilling Efficient Reasoning Models
2 days ago
•
15
Projected Abliteration
26 days ago
•
26
AI Model Optimization More Flexible Than Ever
3 days ago
•
12
ViDoRe V3: a comprehensive evaluation of retrieval for enterprise use-cases
16 days ago
•
49
The Heterogeneous Feature of RoPE-based Attention in Long-Context LLMs
5 days ago
•
11
Uncensor any LLM with abliteration
Jun 13, 2024
•
722
KV Caching Explained: Optimizing Transformer Inference Efficiency
Jan 30
•
175
The Pharmome Map: a comprehensive public dataset for drug-target interaction modeling
2 days ago
•
9
The 1 Billion Token Challenge: Finding the Perfect Pre-training Mix
18 days ago
•
42
Norm-Preserving Biprojected Abliteration
14 days ago
•
14
Granite 4.0 Nano: Just how small can you go?
23 days ago
•
119
Why Did MiniMax M2 End Up as a Full Attention Model?
22 days ago
•
65
🧠 SQaLe: Enabling new Text-to-SQL models with our massive dataset
1 day ago
•
6
Join the AMD Open Robotics Hackathon
7 days ago
•
6
To Think or Not to Think: A Router for Hybrid LLMs
4 days ago
•
6
PEFT: Parameter-Efficient Fine-Tuning Methods for LLMs
Jan 24
•
49
Visualizing How VLMs Work
Oct 7
•
45
leaderboard
evaluation
nlp
Arabic Leaderboards: Introducing Arabic Instruction Following, Updating AraGen, and More
+2
20
April 8, 2025
math-verify
open-llm-leaderboard
leaderboard
Fixing Open LLM Leaderboard with Math-Verify
30
February 14, 2025
nlp
research
leaderboard
The Open Arabic LLM Leaderboard 2
+3
36
February 10, 2025
open-llm-leaderboard
leaderboard
energy_efficiency
CO₂ Emissions and Models Performance: Insights from the Open LLM Leaderboard
21
January 9, 2025
leaderboard
research
collaboration
Evaluating Audio Reasoning with Big Bench Audio
26
December 20, 2024
leaderboard
evaluation
nlp
Rethinking LLM Evaluation with 3C3H: AraGen Benchmark and Leaderboard
+1
38
December 4, 2024
community
research
nlp
Letting Large Models Debate: The First Multilingual LLM Debate Competition
+8
33
November 20, 2024
community
research
nlp
Introducing the Open Leaderboard for Japanese LLMs!
+2
39
November 20, 2024
leaderboard
arena
collaboration
Judge Arena: Benchmarking LLMs as Evaluators
+4
58
November 19, 2024
leaderboard
collaboration
community
Introducing the Open FinLLM Leaderboard
+9
79
October 4, 2024
nlp
research
leaderboard
🇨🇿 BenCzechMark - Can your LLM Understand Czech?
+7
23
October 1, 2024
ai4math
nlp
community
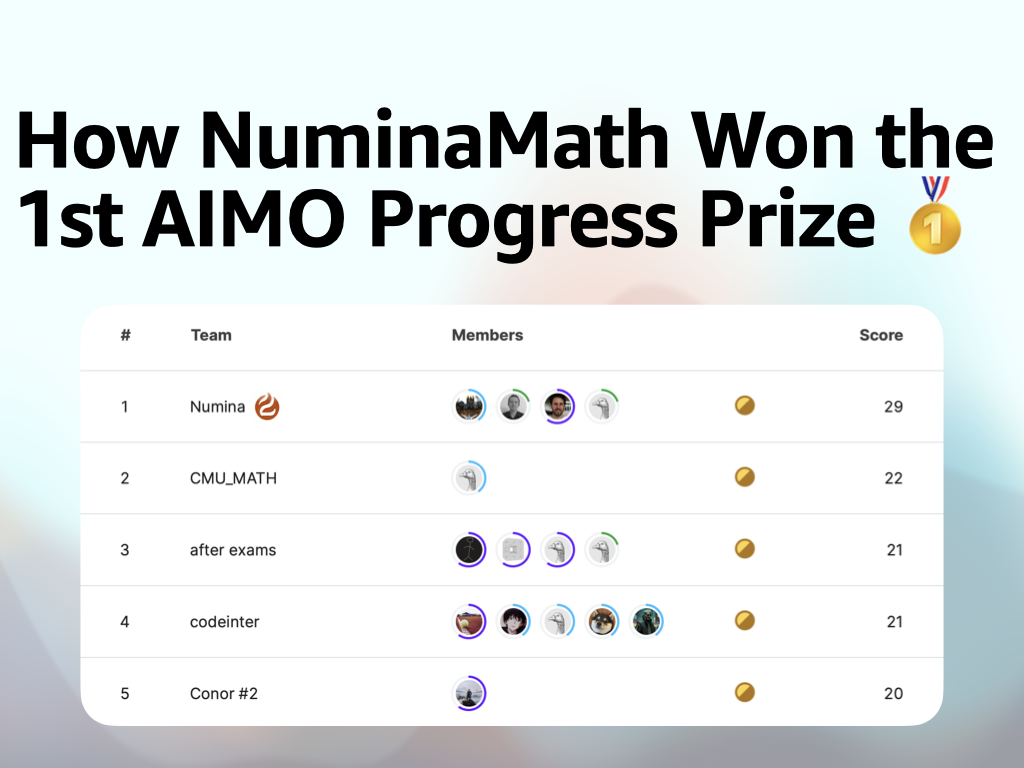
How NuminaMath Won the 1st AIMO Progress Prize
+4
122
July 11, 2024
agents
smolagents
nlp
Our Transformers Code Agent beats the GAIA benchmark 🏅
98
July 1, 2024
leaderboard
research
collaboration
BigCodeBench: The Next Generation of HumanEval
+5
52
June 18, 2024
Previous
1
2
3
Next
Community Articles
Sort: Trending
We’re open-sourcing our text-to-image model and the process behind it
9 days ago
•
65
Text-to-image Architectural Experiments
7 days ago
•
32
Introducing Cogito v2.1
1 day ago
•
16
Apriel-H1: The Surprising Key to Distilling Efficient Reasoning Models
2 days ago
•
15
Projected Abliteration
26 days ago
•
26
AI Model Optimization More Flexible Than Ever
3 days ago
•
12
ViDoRe V3: a comprehensive evaluation of retrieval for enterprise use-cases
16 days ago
•
49
The Heterogeneous Feature of RoPE-based Attention in Long-Context LLMs
5 days ago
•
11
Uncensor any LLM with abliteration
Jun 13, 2024
•
722
KV Caching Explained: Optimizing Transformer Inference Efficiency
Jan 30
•
175
The Pharmome Map: a comprehensive public dataset for drug-target interaction modeling
2 days ago
•
9
The 1 Billion Token Challenge: Finding the Perfect Pre-training Mix
18 days ago
•
42
Norm-Preserving Biprojected Abliteration
14 days ago
•
14
Granite 4.0 Nano: Just how small can you go?
23 days ago
•
119
Why Did MiniMax M2 End Up as a Full Attention Model?
22 days ago
•
65
🧠 SQaLe: Enabling new Text-to-SQL models with our massive dataset
1 day ago
•
6
Join the AMD Open Robotics Hackathon
7 days ago
•
6
To Think or Not to Think: A Router for Hybrid LLMs
4 days ago
•
6
PEFT: Parameter-Efficient Fine-Tuning Methods for LLMs
Jan 24
•
49
Visualizing How VLMs Work
Oct 7
•
45
View all articles