
Upload 112 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +5 -0
- LICENSE +201 -0
- README.md +252 -1
- cog.yaml +17 -0
- download-weights.sh +13 -0
- figs/ETH_BSRGAN.png +3 -0
- figs/ETH_LR.png +3 -0
- figs/ETH_SwinIR-L.png +3 -0
- figs/ETH_SwinIR.png +3 -0
- figs/ETH_realESRGAN.jpg +0 -0
- figs/OST_009_crop_BSRGAN.png +0 -0
- figs/OST_009_crop_LR.png +0 -0
- figs/OST_009_crop_SwinIR-L.png +0 -0
- figs/OST_009_crop_SwinIR.png +0 -0
- figs/OST_009_crop_realESRGAN.png +3 -0
- figs/SwinIR_archi.png +0 -0
- figs/classic_image_sr.png +0 -0
- figs/classic_image_sr_visual.png +0 -0
- figs/color_image_denoising.png +0 -0
- figs/gray_image_denoising.png +0 -0
- figs/jepg_compress_artfact_reduction.png +0 -0
- figs/lightweight_image_sr.png +0 -0
- figs/real_world_image_sr.png +0 -0
- main_test_swinir.py +309 -0
- model_zoo/README.md +3 -0
- models/network_swinir.py +867 -0
- predict.py +159 -0
- testsets/McMaster/1.tif +0 -0
- testsets/McMaster/10.tif +0 -0
- testsets/McMaster/11.tif +0 -0
- testsets/McMaster/12.tif +0 -0
- testsets/McMaster/13.tif +0 -0
- testsets/McMaster/14.tif +0 -0
- testsets/McMaster/15.tif +0 -0
- testsets/McMaster/16.tif +0 -0
- testsets/McMaster/17.tif +0 -0
- testsets/McMaster/18.tif +0 -0
- testsets/McMaster/2.tif +0 -0
- testsets/McMaster/3.tif +0 -0
- testsets/McMaster/4.tif +0 -0
- testsets/McMaster/5.tif +0 -0
- testsets/McMaster/6.tif +0 -0
- testsets/McMaster/7.tif +0 -0
- testsets/McMaster/8.tif +0 -0
- testsets/McMaster/9.tif +0 -0
- testsets/RealSRSet+5images/00003.png +0 -0
- testsets/RealSRSet+5images/0014.jpg +0 -0
- testsets/RealSRSet+5images/0030.jpg +0 -0
- testsets/RealSRSet+5images/ADE_val_00000114.jpg +0 -0
- testsets/RealSRSet+5images/Lincoln.png +0 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
figs/ETH_BSRGAN.png filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
figs/ETH_LR.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
figs/ETH_SwinIR-L.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
figs/ETH_SwinIR.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
figs/OST_009_crop_realESRGAN.png filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [2021] [SwinIR Authors]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,3 +1,254 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SwinIR: Image Restoration Using Swin Transformer
|
| 2 |
+
[Jingyun Liang](https://jingyunliang.github.io), [Jiezhang Cao](https://www.jiezhangcao.com/), [Guolei Sun](https://vision.ee.ethz.ch/people-details.MjYzMjMw.TGlzdC8zMjg5LC0xOTcxNDY1MTc4.html), [Kai Zhang](https://cszn.github.io/), [Luc Van Gool](https://scholar.google.com/citations?user=TwMib_QAAAAJ&hl=en), [Radu Timofte](http://people.ee.ethz.ch/~timofter/)
|
| 3 |
+
|
| 4 |
+
Computer Vision Lab, ETH Zurich
|
| 5 |
+
|
| 6 |
---
|
| 7 |
+
|
| 8 |
+
[](https://arxiv.org/abs/2108.10257)
|
| 9 |
+
[](https://github.com/JingyunLiang/SwinIR)
|
| 10 |
+
[](https://github.com/JingyunLiang/SwinIR/releases)
|
| 11 |
+

|
| 12 |
+
[ <a href="https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="google colab logo"></a>](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb)
|
| 13 |
+
<a href="https://replicate.ai/jingyunliang/swinir"><img src="https://img.shields.io/static/v1?label=Replicate&message=Demo and Docker Image&color=blue"></a>
|
| 14 |
+
[](https://playtorch.dev/snack/@playtorch/swinir/)
|
| 15 |
+
[Gradio Web Demo](https://huggingface.co/spaces/akhaliq/SwinIR)
|
| 16 |
+
|
| 17 |
+
This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Window Transformer
|
| 18 |
+
([arxiv](https://arxiv.org/pdf/2108.10257.pdf), [supp](https://github.com/JingyunLiang/SwinIR/releases), [pretrained models](https://github.com/JingyunLiang/SwinIR/releases), [visual results](https://github.com/JingyunLiang/SwinIR/releases)). SwinIR achieves **state-of-the-art performance** in
|
| 19 |
+
- bicubic/lighweight/real-world image SR
|
| 20 |
+
- grayscale/color image denoising
|
| 21 |
+
- grayscale/color JPEG compression artifact reduction
|
| 22 |
+
|
| 23 |
+
</br>
|
| 24 |
+
|
| 25 |
+
:rocket: :rocket: :rocket: **News**:
|
| 26 |
+
- **Aug. 16, 2022**: Add PlayTorch Demo on running the real-world image SR model on mobile devices [](https://playtorch.dev/snack/@playtorch/swinir/).
|
| 27 |
+
- **Aug. 01, 2022**: Add pretrained models and results on JPEG compression artifact reduction for color images.
|
| 28 |
+
- **Jun. 10, 2022**: See our work on video restoration :fire::fire::fire: [VRT: A Video Restoration Transformer](https://github.com/JingyunLiang/VRT)
|
| 29 |
+
[](https://github.com/JingyunLiang/VRT)
|
| 30 |
+
[](https://github.com/JingyunLiang/VRT/releases)
|
| 31 |
+
and [RVRT: Recurrent Video Restoration Transformer](https://github.com/JingyunLiang/RVRT)
|
| 32 |
+
[](https://github.com/JingyunLiang/RVRT)
|
| 33 |
+
[](https://github.com/JingyunLiang/RVRT/releases)
|
| 34 |
+
for video SR, video deblurring, video denoising, video frame interpolation and space-time video SR.
|
| 35 |
+
- **Sep. 07, 2021**: We provide an interactive online Colab demo for real-world image SR <a href="https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="google colab logo"></a>:fire: for comparison with [the first practical degradation model BSRGAN (ICCV2021) ](https://github.com/cszn/BSRGAN) and a recent model RealESRGAN. Try to super-resolve your own images on Colab!
|
| 36 |
+
|
| 37 |
+
|Real-World Image (x4)|[BSRGAN, ICCV2021](https://github.com/cszn/BSRGAN)|[Real-ESRGAN](https://github.com/xinntao/Real-ESRGAN)|SwinIR (ours)|SwinIR-Large (ours)|
|
| 38 |
+
| :--- | :---: | :-----: | :-----: | :-----: |
|
| 39 |
+
| <img width="200" src="figs/ETH_LR.png">|<img width="200" src="figs/ETH_BSRGAN.png">|<img width="200" src="figs/ETH_realESRGAN.jpg">|<img width="200" src="figs/ETH_SwinIR.png">|<img width="200" src="figs/ETH_SwinIR-L.png">
|
| 40 |
+
|<img width="200" src="figs/OST_009_crop_LR.png">|<img width="200" src="figs/OST_009_crop_BSRGAN.png">|<img width="200" src="figs/OST_009_crop_realESRGAN.png">|<img width="200" src="figs/OST_009_crop_SwinIR.png">|<img width="200" src="figs/OST_009_crop_SwinIR-L.png">|
|
| 41 |
+
|
| 42 |
+
- ***Aug. 26, 2021**: See our recent work on [real-world image SR: a pratical degrdation model BSRGAN, ICCV2021](https://github.com/cszn/BSRGAN)
|
| 43 |
+
[](https://github.com/cszn/BSRGAN)*
|
| 44 |
+
- ***Aug. 26, 2021**: See our recent work on [generative modelling of image SR and image rescaling: normalizing-flow-based HCFlow, ICCV2021](https://github.com/JingyunLiang/HCFlow)
|
| 45 |
+
[](https://github.com/JingyunLiang/HCFlow)[ <a href="https://colab.research.google.com/gist/JingyunLiang/cdb3fef89ebd174eaa43794accb6f59d/hcflow-demo-on-x8-face-image-sr.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="google colab logo"></a>](https://colab.research.google.com/gist/JingyunLiang/cdb3fef89ebd174eaa43794accb6f59d/hcflow-demo-on-x8-face-image-sr.ipynb)*
|
| 46 |
+
- ***Aug. 26, 2021**: See our recent work on [blind SR: spatially variant kernel estimation (MANet, ICCV2021)](https://github.com/JingyunLiang/MANet) [](https://github.com/JingyunLiang/MANet)
|
| 47 |
+
[ <a href="https://colab.research.google.com/gist/JingyunLiang/4ed2524d6e08343710ee408a4d997e1c/manet-demo-on-spatially-variant-kernel-estimation.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="google colab logo"></a>](https://colab.research.google.com/gist/JingyunLiang/4ed2524d6e08343710ee408a4d997e1c/manet-demo-on-spatially-variant-kernel-estimation.ipynb) and [unsupervised kernel estimation (FKP, CVPR2021)](https://github.com/JingyunLiang/FKP)
|
| 48 |
+
[](https://github.com/JingyunLiang/FKP)*
|
| 49 |
+
|
| 50 |
---
|
| 51 |
+
|
| 52 |
+
> Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
|
| 53 |
+
><p align="center">
|
| 54 |
+
<img width="800" src="figs/SwinIR_archi.png">
|
| 55 |
+
</p>
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
#### Contents
|
| 60 |
+
|
| 61 |
+
1. [Training](#Training)
|
| 62 |
+
1. [Testing](#Testing)
|
| 63 |
+
1. [Results](#Results)
|
| 64 |
+
1. [Citation](#Citation)
|
| 65 |
+
1. [License and Acknowledgement](#License-and-Acknowledgement)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
### Training
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
Used training and testing sets can be downloaded as follows:
|
| 72 |
+
|
| 73 |
+
| Task | Training Set | Testing Set| Visual Results |
|
| 74 |
+
|:----------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:| :---: | :---: |
|
| 75 |
+
| classical/lightweight image SR | [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) or DIV2K +[Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) | Set5 + Set14 + BSD100 + Urban100 + Manga109 [download all](https://drive.google.com/drive/folders/1B3DJGQKB6eNdwuQIhdskA64qUuVKLZ9u) | [here](https://github.com/JingyunLiang/SwinIR/releases) |
|
| 76 |
+
| real-world image SR | SwinIR-M (middle size): [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) +[Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) + [OST](https://openmmlab.oss-cn-hangzhou.aliyuncs.com/datasets/OST_dataset.zip) ([alternative link](https://drive.google.com/drive/folders/1iZfzAxAwOpeutz27HC56_y5RNqnsPPKr), 10324 images for sky,water,grass,mountain,building,plant,animal) <br /> SwinIR-L (large size): DIV2K + Flickr2K + OST + [WED](http://ivc.uwaterloo.ca/database/WaterlooExploration/exploration_database_and_code.rar)(4744 images) + [FFHQ](https://drive.google.com/drive/folders/1tZUcXDBeOibC6jcMCtgRRz67pzrAHeHL) (first 2000 images, face) + Manga109 (manga) + [SCUT-CTW1500](https://universityofadelaide.box.com/shared/static/py5uwlfyyytbb2pxzq9czvu6fuqbjdh8.zip) (first 100 training images, texts) <br /><br /> ***We use the pionnerring practical degradation model from [BSRGAN, ICCV2021 ](https://github.com/cszn/BSRGAN)** | [RealSRSet+5images](https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/RealSRSet+5images.zip) | [here](https://github.com/JingyunLiang/SwinIR/releases) |
|
| 77 |
+
| color/grayscale image denoising | [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) + [Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) + [BSD500](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/BSR/BSR_bsds500.tgz) (400 training&testing images) + [WED](http://ivc.uwaterloo.ca/database/WaterlooExploration/exploration_database_and_code.rar)(4744 images) <br /><br /> *BSD68/BSD100 images are not used in training. | grayscale: Set12 + BSD68 + Urban100 <br /> color: CBSD68 + Kodak24 + McMaster + Urban100 [download all](https://github.com/cszn/FFDNet/tree/master/testsets) | [here](https://github.com/JingyunLiang/SwinIR/releases) |
|
| 78 |
+
| grayscale/color JPEG compression artifact reduction | [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) + [Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) + [BSD500](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/BSR/BSR_bsds500.tgz) (400 training&testing images) + [WED](http://ivc.uwaterloo.ca/database/WaterlooExploration/exploration_database_and_code.rar)(4744 images) | grayscale: Classic5 +LIVE1 [download all](https://github.com/cszn/DnCNN/tree/master/testsets) | [here](https://github.com/JingyunLiang/SwinIR/releases) |
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
<!--
|
| 82 |
+
| Task | Training Set | Testing Set| Pretrained Model and Visual Results of SwinIR |
|
| 83 |
+
| :--- | :---: | :---: |:---: |
|
| 84 |
+
| image denoising (real) | [SIDD-Medium-sRGB](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php) (320 images, [preprocess]()) + [RENOIR](http://ani.stat.fsu.edu/~abarbu/Renoir.html) (221 images, [preprocess](https://github.com/zsyOAOA/DANet/blob/master/datasets/preparedata/Renoir_big2small_all.py)) + [Poly](https://github.com/csjunxu/PolyU-Real-World-Noisy-Images-Dataset) (40 images in ./OriginalImages) | [SIDD validation set](https://drive.google.com/drive/folders/1S44fHXaVxAYW3KLNxK41NYCnyX9S79su) (1280 patches, identical to official [.mat](https://www.eecs.yorku.ca/~kamel/sidd/benchmark.php) version) + [DND](https://noise.visinf.tu-darmstadt.de/downloads/) (pre-defined 100 patches of 50 images, [online eval](https://noise.visinf.tu-darmstadt.de/submit/)) + [Nam](https://www.dropbox.com/s/24kds7c436i5i11/real_image_noise_dataset.zip?dl=0) (random 100 patches of 17 images, [preprocess](https://github.com/zsyOAOA/DANet/blob/master/datasets/preparedata/Nam_patch_prepare.py))|[download model]() [download results]() |
|
| 85 |
+
| image deblurring (synthetic) | [GoPro](https://drive.google.com/drive/folders/1AsgIP9_X0bg0olu2-1N6karm2x15cJWE) (2103 training images) | [GoPro](https://drive.google.com/drive/folders/1a2qKfXWpNuTGOm2-Jex8kfNSzYJLbqkf) (1111 images) + [HIDE](https://drive.google.com/drive/folders/1nRsTXj4iTUkTvBhTcGg8cySK8nd3vlhK) (2050 images) + [RealBlur_J](https://drive.google.com/drive/folders/1KYtzeKCiDRX9DSvC-upHrCqvC4sPAiJ1) (real blur, 980 images) + [RealBlur_R](https://drive.google.com/drive/folders/1EwDoajf5nStPIAcU4s9rdc8SPzfm3tW1) (real blur, 980 images) | [download model]() [download results]()|
|
| 86 |
+
| image deraining (synthetic) | [Multiple datasets](https://drive.google.com/drive/folders/1Hnnlc5kI0v9_BtfMytC2LR5VpLAFZtVe) (13711 training images, see Table 1 of [MPRNet](https://github.com/swz30/MPRNet) for details.) | Rain100H (100 images) + Rain100L (100 images) + Test100 (100 images) + Test2800 (2800 images) + Test1200 (1200 images), [download all](https://drive.google.com/drive/folders/1PDWggNh8ylevFmrjo-JEvlmqsDlWWvZs) | [download model]() [download results]()|
|
| 87 |
+
|
| 88 |
+
Note: above datasets may come from the official release or some awesome collections ([BasicSR](https://github.com/xinntao/BasicSR), [MPRNet](https://github.com/swz30/MPRNet)).
|
| 89 |
+
|
| 90 |
+
-->
|
| 91 |
+
|
| 92 |
+
The training code is at [KAIR](https://github.com/cszn/KAIR/blob/master/docs/README_SwinIR.md).
|
| 93 |
+
|
| 94 |
+
## Testing (without preparing datasets)
|
| 95 |
+
For your convience, we provide some example datasets (~20Mb) in `/testsets`.
|
| 96 |
+
If you just want codes, downloading `models/network_swinir.py`, `utils/util_calculate_psnr_ssim.py` and `main_test_swinir.py` is enough.
|
| 97 |
+
Following commands will download [pretrained models](https://github.com/JingyunLiang/SwinIR/releases) **automatically** and put them in `model_zoo/swinir`.
|
| 98 |
+
**[All visual results of SwinIR can be downloaded here](https://github.com/JingyunLiang/SwinIR/releases)**.
|
| 99 |
+
|
| 100 |
+
We also provide an [online Colab demo for real-world image SR <a href="https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="google colab logo"></a>](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb) for comparison with [the first practical degradation model BSRGAN (ICCV2021) ](https://github.com/cszn/BSRGAN) and a recent model [RealESRGAN](https://github.com/xinntao/Real-ESRGAN). Try to test your own images on Colab!
|
| 101 |
+
|
| 102 |
+
We provide a PlayTorch demo [](https://playtorch.dev/snack/@playtorch/swinir/) for real-world image SR to showcase how to run the SwinIR model in mobile application built with React Native.
|
| 103 |
+
|
| 104 |
+
```bash
|
| 105 |
+
# 001 Classical Image Super-Resolution (middle size)
|
| 106 |
+
# Note that --training_patch_size is just used to differentiate two different settings in Table 2 of the paper. Images are NOT tested patch by patch.
|
| 107 |
+
# (setting1: when model is trained on DIV2K and with training_patch_size=48)
|
| 108 |
+
python main_test_swinir.py --task classical_sr --scale 2 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x2.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
|
| 109 |
+
python main_test_swinir.py --task classical_sr --scale 3 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x3.pth --folder_lq testsets/Set5/LR_bicubic/X3 --folder_gt testsets/Set5/HR
|
| 110 |
+
python main_test_swinir.py --task classical_sr --scale 4 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x4.pth --folder_lq testsets/Set5/LR_bicubic/X4 --folder_gt testsets/Set5/HR
|
| 111 |
+
python main_test_swinir.py --task classical_sr --scale 8 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x8.pth --folder_lq testsets/Set5/LR_bicubic/X8 --folder_gt testsets/Set5/HR
|
| 112 |
+
|
| 113 |
+
# (setting2: when model is trained on DIV2K+Flickr2K and with training_patch_size=64)
|
| 114 |
+
python main_test_swinir.py --task classical_sr --scale 2 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x2.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
|
| 115 |
+
python main_test_swinir.py --task classical_sr --scale 3 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x3.pth --folder_lq testsets/Set5/LR_bicubic/X3 --folder_gt testsets/Set5/HR
|
| 116 |
+
python main_test_swinir.py --task classical_sr --scale 4 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x4.pth --folder_lq testsets/Set5/LR_bicubic/X4 --folder_gt testsets/Set5/HR
|
| 117 |
+
python main_test_swinir.py --task classical_sr --scale 8 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x8.pth --folder_lq testsets/Set5/LR_bicubic/X8 --folder_gt testsets/Set5/HR
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
# 002 Lightweight Image Super-Resolution (small size)
|
| 121 |
+
python main_test_swinir.py --task lightweight_sr --scale 2 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x2.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
|
| 122 |
+
python main_test_swinir.py --task lightweight_sr --scale 3 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x3.pth --folder_lq testsets/Set5/LR_bicubic/X3 --folder_gt testsets/Set5/HR
|
| 123 |
+
python main_test_swinir.py --task lightweight_sr --scale 4 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x4.pth --folder_lq testsets/Set5/LR_bicubic/X4 --folder_gt testsets/Set5/HR
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
# 003 Real-World Image Super-Resolution (use --tile 400 if you run out-of-memory)
|
| 127 |
+
# (middle size)
|
| 128 |
+
python main_test_swinir.py --task real_sr --scale 4 --model_path model_zoo/swinir/003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth --folder_lq testsets/RealSRSet+5images --tile
|
| 129 |
+
|
| 130 |
+
# (larger size + trained on more datasets)
|
| 131 |
+
python main_test_swinir.py --task real_sr --scale 4 --large_model --model_path model_zoo/swinir/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth --folder_lq testsets/RealSRSet+5images
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
# 004 Grayscale Image Deoising (middle size)
|
| 135 |
+
python main_test_swinir.py --task gray_dn --noise 15 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/Set12
|
| 136 |
+
python main_test_swinir.py --task gray_dn --noise 25 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise25.pth --folder_gt testsets/Set12
|
| 137 |
+
python main_test_swinir.py --task gray_dn --noise 50 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise50.pth --folder_gt testsets/Set12
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
# 005 Color Image Deoising (middle size)
|
| 141 |
+
python main_test_swinir.py --task color_dn --noise 15 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/McMaster
|
| 142 |
+
python main_test_swinir.py --task color_dn --noise 25 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth --folder_gt testsets/McMaster
|
| 143 |
+
python main_test_swinir.py --task color_dn --noise 50 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth --folder_gt testsets/McMaster
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
# 006 JPEG Compression Artifact Reduction (middle size, using window_size=7 because JPEG encoding uses 8x8 blocks)
|
| 147 |
+
# grayscale
|
| 148 |
+
python main_test_swinir.py --task jpeg_car --jpeg 10 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth --folder_gt testsets/classic5
|
| 149 |
+
python main_test_swinir.py --task jpeg_car --jpeg 20 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth --folder_gt testsets/classic5
|
| 150 |
+
python main_test_swinir.py --task jpeg_car --jpeg 30 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth --folder_gt testsets/classic5
|
| 151 |
+
python main_test_swinir.py --task jpeg_car --jpeg 40 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth --folder_gt testsets/classic5
|
| 152 |
+
|
| 153 |
+
# color
|
| 154 |
+
python main_test_swinir.py --task color_jpeg_car --jpeg 10 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg10.pth --folder_gt testsets/LIVE1
|
| 155 |
+
python main_test_swinir.py --task color_jpeg_car --jpeg 20 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg20.pth --folder_gt testsets/LIVE1
|
| 156 |
+
python main_test_swinir.py --task color_jpeg_car --jpeg 30 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg30.pth --folder_gt testsets/LIVE1
|
| 157 |
+
python main_test_swinir.py --task color_jpeg_car --jpeg 40 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg40.pth --folder_gt testsets/LIVE1
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
---
|
| 162 |
+
|
| 163 |
+
## Results
|
| 164 |
+
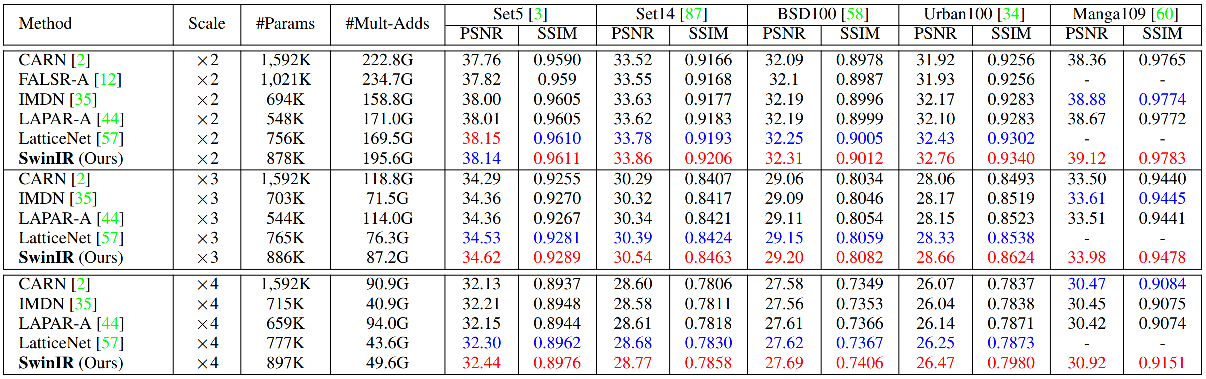
We achieved state-of-the-art performance on classical/lightweight/real-world image SR, grayscale/color image denoising and JPEG compression artifact reduction. Detailed results can be found in the [paper](https://arxiv.org/abs/2108.10257). All visual results of SwinIR can be downloaded [here](https://github.com/JingyunLiang/SwinIR/releases).
|
| 165 |
+
|
| 166 |
+
<details>
|
| 167 |
+
<summary>Classical Image Super-Resolution (click me)</summary>
|
| 168 |
+
<p align="center">
|
| 169 |
+
<img width="900" src="figs/classic_image_sr.png">
|
| 170 |
+
<img width="900" src="figs/classic_image_sr_visual.png">
|
| 171 |
+
</p>
|
| 172 |
+
|
| 173 |
+
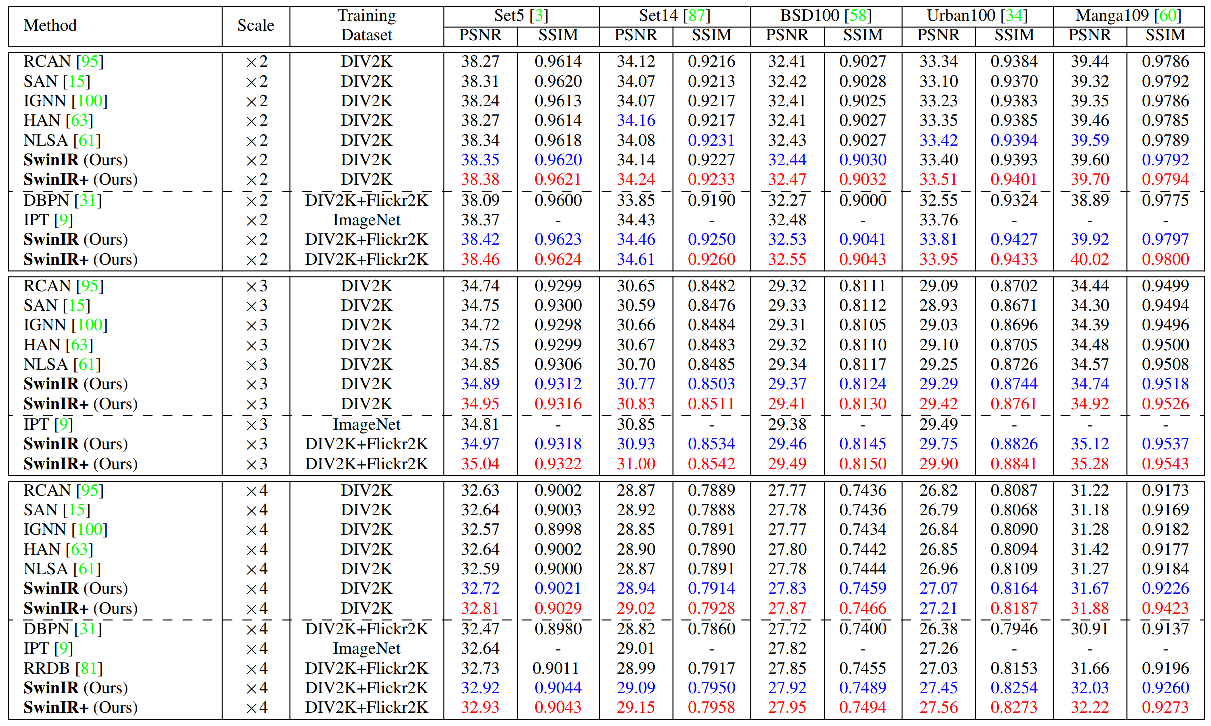
- More detailed comparison between SwinIR and a representative CNN-based model RCAN (classical image SR, X4)
|
| 174 |
+
|
| 175 |
+
| Method | Training Set | Training time <br /> (8GeForceRTX2080Ti <br /> batch=32, iter=500k) |Y-PSNR/Y-SSIM <br /> on Manga109 | Run time <br /> (1GeForceRTX2080Ti,<br /> on 256x256 LR image)* | #Params | #FLOPs | Testing memory |
|
| 176 |
+
| :--- | :---: | :-----: | :---: | :---: | :---: | :---: | :---: |
|
| 177 |
+
| RCAN | DIV2K | 1.6 days | 31.22/0.9173 | 0.180s | 15.6M | 850.6G | 593.1M |
|
| 178 |
+
| SwinIR | DIV2K | 1.8 days |31.67/0.9226 | 0.539s | 11.9M | 788.6G | 986.8M |
|
| 179 |
+
|
| 180 |
+
\* We re-test the runtime when the GPU is idle. We refer to the evluation code [here](https://github.com/cszn/KAIR/blob/master/main_challenge_sr.py).
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
- Results on DIV2K-validation (100 images)
|
| 184 |
+
|
| 185 |
+
| Training Set | scale factor | PSNR (RGB) | PSNR (Y) | SSIM (RGB) | SSIM (Y) |
|
| 186 |
+
| :--- | :---: | :---: | :---: | :---: | :---: |
|
| 187 |
+
| DIV2K (800 images) | 2 | 35.25 | 36.77 | 0.9423 | 0.9500 |
|
| 188 |
+
| DIV2K+Flickr2K (2650 images) | 2 | 35.34 | 36.86 | 0.9430 |0.9507 |
|
| 189 |
+
| DIV2K (800 images) | 3 | 31.50 | 32.97 | 0.8832 |0.8965 |
|
| 190 |
+
| DIV2K+Flickr2K (2650 images) | 3 | 31.63 | 33.10 | 0.8854 |0.8985 |
|
| 191 |
+
| DIV2K (800 images) | 4 | 29.48 | 30.94 | 0.8311|0.8492 |
|
| 192 |
+
| DIV2K+Flickr2K (2650 images) | 4 | 29.63 | 31.08 | 0.8347|0.8523 |
|
| 193 |
+
|
| 194 |
+
</details>
|
| 195 |
+
|
| 196 |
+
<details>
|
| 197 |
+
<summary>Lightweight Image Super-Resolution</summary>
|
| 198 |
+
<p align="center">
|
| 199 |
+
<img width="900" src="figs/lightweight_image_sr.png">
|
| 200 |
+
</p>
|
| 201 |
+
</details>
|
| 202 |
+
|
| 203 |
+
<details>
|
| 204 |
+
<summary>Real-World Image Super-Resolution</summary>
|
| 205 |
+
<p align="center">
|
| 206 |
+
<img width="900" src="figs/real_world_image_sr.png">
|
| 207 |
+
</p>
|
| 208 |
+
</details>
|
| 209 |
+
|
| 210 |
+
<details>
|
| 211 |
+
<summary>Grayscale Image Deoising</summary>
|
| 212 |
+
<p align="center">
|
| 213 |
+
<img width="900" src="figs/gray_image_denoising.png">
|
| 214 |
+
</p>
|
| 215 |
+
</details>
|
| 216 |
+
|
| 217 |
+
<details>
|
| 218 |
+
<summary>Color Image Deoising</summary>
|
| 219 |
+
<p align="center">
|
| 220 |
+
<img width="900" src="figs/color_image_denoising.png">
|
| 221 |
+
</p>
|
| 222 |
+
</details>
|
| 223 |
+
|
| 224 |
+
<details>
|
| 225 |
+
<summary>JPEG Compression Artifact Reduction</summary>
|
| 226 |
+
|
| 227 |
+
on grayscale images
|
| 228 |
+
<p align="center">
|
| 229 |
+
<img width="900" src="figs/jepg_compress_artfact_reduction.png">
|
| 230 |
+
</p>
|
| 231 |
+
|
| 232 |
+
on color images
|
| 233 |
+
|
| 234 |
+
| Training Set | quality factor | PSNR (RGB) | PSNR-B (RGB) | SSIM (RGB) |
|
| 235 |
+
|:-------------|:--------------:|:----------:|:------------:|:----------:|
|
| 236 |
+
| LIVE1 | 10 | 28.06 | 27.76 | 0.8089 |
|
| 237 |
+
| LIVE1 | 20 | 30.45 | 29.97 | 0.8741 |
|
| 238 |
+
| LIVE1 | 30 | 31.82 | 31.24 | 0.9018 |
|
| 239 |
+
| LIVE1 | 40 | 32.75 | 32.12 | 0.9174 |
|
| 240 |
+
</details>
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
## Citation
|
| 245 |
+
@article{liang2021swinir,
|
| 246 |
+
title={SwinIR: Image Restoration Using Swin Transformer},
|
| 247 |
+
author={Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu},
|
| 248 |
+
journal={arXiv preprint arXiv:2108.10257},
|
| 249 |
+
year={2021}
|
| 250 |
+
}
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
## License and Acknowledgement
|
| 254 |
+
This project is released under the Apache 2.0 license. The codes are based on [Swin Transformer](https://github.com/microsoft/Swin-Transformer) and [KAIR](https://github.com/cszn/KAIR). Please also follow their licenses. Thanks for their awesome works.
|
cog.yaml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build:
|
| 2 |
+
gpu: true
|
| 3 |
+
python_version: "3.8"
|
| 4 |
+
system_packages:
|
| 5 |
+
- "libgl1-mesa-glx"
|
| 6 |
+
- "libglib2.0-0"
|
| 7 |
+
python_packages:
|
| 8 |
+
- "torchvision==0.9.0"
|
| 9 |
+
- "torch==1.8.0"
|
| 10 |
+
- "numpy==1.19.4"
|
| 11 |
+
- "opencv-python==4.4.0.46"
|
| 12 |
+
- "tqdm==4.62.2"
|
| 13 |
+
- "Pillow==8.3.2"
|
| 14 |
+
- "timm==0.4.12"
|
| 15 |
+
- "ipython==7.19.0"
|
| 16 |
+
|
| 17 |
+
predict: "predict.py:Predictor"
|
download-weights.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/sh
|
| 2 |
+
|
| 3 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth -P experiments/pretrained_models
|
| 4 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth -P experiments/pretrained_models
|
| 5 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/004_grayDN_DFWB_s128w8_SwinIR-M_noise25.pth -P experiments/pretrained_models
|
| 6 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/004_grayDN_DFWB_s128w8_SwinIR-M_noise50.pth -P experiments/pretrained_models
|
| 7 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth -P experiments/pretrained_models
|
| 8 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth -P experiments/pretrained_models
|
| 9 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth -P experiments/pretrained_models
|
| 10 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth -P experiments/pretrained_models
|
| 11 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth -P experiments/pretrained_models
|
| 12 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth -P experiments/pretrained_models
|
| 13 |
+
wget https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth -P experiments/pretrained_models
|
figs/ETH_BSRGAN.png
ADDED

|
Git LFS Details
|
figs/ETH_LR.png
ADDED

|
Git LFS Details
|
figs/ETH_SwinIR-L.png
ADDED

|
Git LFS Details
|
figs/ETH_SwinIR.png
ADDED

|
Git LFS Details
|
figs/ETH_realESRGAN.jpg
ADDED

|
figs/OST_009_crop_BSRGAN.png
ADDED

|
figs/OST_009_crop_LR.png
ADDED

|
figs/OST_009_crop_SwinIR-L.png
ADDED

|
figs/OST_009_crop_SwinIR.png
ADDED

|
figs/OST_009_crop_realESRGAN.png
ADDED

|
Git LFS Details
|
figs/SwinIR_archi.png
ADDED

|
figs/classic_image_sr.png
ADDED
|
figs/classic_image_sr_visual.png
ADDED

|
figs/color_image_denoising.png
ADDED

|
figs/gray_image_denoising.png
ADDED

|
figs/jepg_compress_artfact_reduction.png
ADDED

|
figs/lightweight_image_sr.png
ADDED
|
figs/real_world_image_sr.png
ADDED

|
main_test_swinir.py
ADDED
|
@@ -0,0 +1,309 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import cv2
|
| 3 |
+
import glob
|
| 4 |
+
import numpy as np
|
| 5 |
+
from collections import OrderedDict
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
import requests
|
| 9 |
+
|
| 10 |
+
from models.network_swinir import SwinIR as net
|
| 11 |
+
from utils import util_calculate_psnr_ssim as util
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def main():
|
| 15 |
+
parser = argparse.ArgumentParser()
|
| 16 |
+
parser.add_argument('--task', type=str, default='color_dn', help='classical_sr, lightweight_sr, real_sr, '
|
| 17 |
+
'gray_dn, color_dn, jpeg_car, color_jpeg_car')
|
| 18 |
+
parser.add_argument('--scale', type=int, default=1, help='scale factor: 1, 2, 3, 4, 8') # 1 for dn and jpeg car
|
| 19 |
+
parser.add_argument('--noise', type=int, default=15, help='noise level: 15, 25, 50')
|
| 20 |
+
parser.add_argument('--jpeg', type=int, default=40, help='scale factor: 10, 20, 30, 40')
|
| 21 |
+
parser.add_argument('--training_patch_size', type=int, default=128, help='patch size used in training SwinIR. '
|
| 22 |
+
'Just used to differentiate two different settings in Table 2 of the paper. '
|
| 23 |
+
'Images are NOT tested patch by patch.')
|
| 24 |
+
parser.add_argument('--large_model', action='store_true', help='use large model, only provided for real image sr')
|
| 25 |
+
parser.add_argument('--model_path', type=str,
|
| 26 |
+
default='model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x2.pth')
|
| 27 |
+
parser.add_argument('--folder_lq', type=str, default=None, help='input low-quality test image folder')
|
| 28 |
+
parser.add_argument('--folder_gt', type=str, default=None, help='input ground-truth test image folder')
|
| 29 |
+
parser.add_argument('--tile', type=int, default=None, help='Tile size, None for no tile during testing (testing as a whole)')
|
| 30 |
+
parser.add_argument('--tile_overlap', type=int, default=32, help='Overlapping of different tiles')
|
| 31 |
+
args = parser.parse_args()
|
| 32 |
+
|
| 33 |
+
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 34 |
+
# set up model
|
| 35 |
+
if os.path.exists(args.model_path):
|
| 36 |
+
print(f'loading model from {args.model_path}')
|
| 37 |
+
else:
|
| 38 |
+
os.makedirs(os.path.dirname(args.model_path), exist_ok=True)
|
| 39 |
+
url = 'https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/{}'.format(os.path.basename(args.model_path))
|
| 40 |
+
r = requests.get(url, allow_redirects=True)
|
| 41 |
+
print(f'downloading model {args.model_path}')
|
| 42 |
+
open(args.model_path, 'wb').write(r.content)
|
| 43 |
+
|
| 44 |
+
model = define_model(args)
|
| 45 |
+
model.eval()
|
| 46 |
+
model = model.to(device)
|
| 47 |
+
|
| 48 |
+
# setup folder and path
|
| 49 |
+
folder, save_dir, border, window_size = setup(args)
|
| 50 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 51 |
+
test_results = OrderedDict()
|
| 52 |
+
test_results['psnr'] = []
|
| 53 |
+
test_results['ssim'] = []
|
| 54 |
+
test_results['psnr_y'] = []
|
| 55 |
+
test_results['ssim_y'] = []
|
| 56 |
+
test_results['psnrb'] = []
|
| 57 |
+
test_results['psnrb_y'] = []
|
| 58 |
+
psnr, ssim, psnr_y, ssim_y, psnrb, psnrb_y = 0, 0, 0, 0, 0, 0
|
| 59 |
+
|
| 60 |
+
for idx, path in enumerate(sorted(glob.glob(os.path.join(folder, '*')))):
|
| 61 |
+
# read image
|
| 62 |
+
imgname, img_lq, img_gt = get_image_pair(args, path) # image to HWC-BGR, float32
|
| 63 |
+
img_lq = np.transpose(img_lq if img_lq.shape[2] == 1 else img_lq[:, :, [2, 1, 0]], (2, 0, 1)) # HCW-BGR to CHW-RGB
|
| 64 |
+
img_lq = torch.from_numpy(img_lq).float().unsqueeze(0).to(device) # CHW-RGB to NCHW-RGB
|
| 65 |
+
|
| 66 |
+
# inference
|
| 67 |
+
with torch.no_grad():
|
| 68 |
+
# pad input image to be a multiple of window_size
|
| 69 |
+
_, _, h_old, w_old = img_lq.size()
|
| 70 |
+
h_pad = (h_old // window_size + 1) * window_size - h_old
|
| 71 |
+
w_pad = (w_old // window_size + 1) * window_size - w_old
|
| 72 |
+
img_lq = torch.cat([img_lq, torch.flip(img_lq, [2])], 2)[:, :, :h_old + h_pad, :]
|
| 73 |
+
img_lq = torch.cat([img_lq, torch.flip(img_lq, [3])], 3)[:, :, :, :w_old + w_pad]
|
| 74 |
+
output = test(img_lq, model, args, window_size)
|
| 75 |
+
output = output[..., :h_old * args.scale, :w_old * args.scale]
|
| 76 |
+
|
| 77 |
+
# save image
|
| 78 |
+
output = output.data.squeeze().float().cpu().clamp_(0, 1).numpy()
|
| 79 |
+
if output.ndim == 3:
|
| 80 |
+
output = np.transpose(output[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
|
| 81 |
+
output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
|
| 82 |
+
cv2.imwrite(f'{save_dir}/{imgname}_SwinIR.png', output)
|
| 83 |
+
|
| 84 |
+
# evaluate psnr/ssim/psnr_b
|
| 85 |
+
if img_gt is not None:
|
| 86 |
+
img_gt = (img_gt * 255.0).round().astype(np.uint8) # float32 to uint8
|
| 87 |
+
img_gt = img_gt[:h_old * args.scale, :w_old * args.scale, ...] # crop gt
|
| 88 |
+
img_gt = np.squeeze(img_gt)
|
| 89 |
+
|
| 90 |
+
psnr = util.calculate_psnr(output, img_gt, crop_border=border)
|
| 91 |
+
ssim = util.calculate_ssim(output, img_gt, crop_border=border)
|
| 92 |
+
test_results['psnr'].append(psnr)
|
| 93 |
+
test_results['ssim'].append(ssim)
|
| 94 |
+
if img_gt.ndim == 3: # RGB image
|
| 95 |
+
psnr_y = util.calculate_psnr(output, img_gt, crop_border=border, test_y_channel=True)
|
| 96 |
+
ssim_y = util.calculate_ssim(output, img_gt, crop_border=border, test_y_channel=True)
|
| 97 |
+
test_results['psnr_y'].append(psnr_y)
|
| 98 |
+
test_results['ssim_y'].append(ssim_y)
|
| 99 |
+
if args.task in ['jpeg_car', 'color_jpeg_car']:
|
| 100 |
+
psnrb = util.calculate_psnrb(output, img_gt, crop_border=border, test_y_channel=False)
|
| 101 |
+
test_results['psnrb'].append(psnrb)
|
| 102 |
+
if args.task in ['color_jpeg_car']:
|
| 103 |
+
psnrb_y = util.calculate_psnrb(output, img_gt, crop_border=border, test_y_channel=True)
|
| 104 |
+
test_results['psnrb_y'].append(psnrb_y)
|
| 105 |
+
print('Testing {:d} {:20s} - PSNR: {:.2f} dB; SSIM: {:.4f}; PSNRB: {:.2f} dB;'
|
| 106 |
+
'PSNR_Y: {:.2f} dB; SSIM_Y: {:.4f}; PSNRB_Y: {:.2f} dB.'.
|
| 107 |
+
format(idx, imgname, psnr, ssim, psnrb, psnr_y, ssim_y, psnrb_y))
|
| 108 |
+
else:
|
| 109 |
+
print('Testing {:d} {:20s}'.format(idx, imgname))
|
| 110 |
+
|
| 111 |
+
# summarize psnr/ssim
|
| 112 |
+
if img_gt is not None:
|
| 113 |
+
ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
|
| 114 |
+
ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
|
| 115 |
+
print('\n{} \n-- Average PSNR/SSIM(RGB): {:.2f} dB; {:.4f}'.format(save_dir, ave_psnr, ave_ssim))
|
| 116 |
+
if img_gt.ndim == 3:
|
| 117 |
+
ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
|
| 118 |
+
ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
|
| 119 |
+
print('-- Average PSNR_Y/SSIM_Y: {:.2f} dB; {:.4f}'.format(ave_psnr_y, ave_ssim_y))
|
| 120 |
+
if args.task in ['jpeg_car', 'color_jpeg_car']:
|
| 121 |
+
ave_psnrb = sum(test_results['psnrb']) / len(test_results['psnrb'])
|
| 122 |
+
print('-- Average PSNRB: {:.2f} dB'.format(ave_psnrb))
|
| 123 |
+
if args.task in ['color_jpeg_car']:
|
| 124 |
+
ave_psnrb_y = sum(test_results['psnrb_y']) / len(test_results['psnrb_y'])
|
| 125 |
+
print('-- Average PSNRB_Y: {:.2f} dB'.format(ave_psnrb_y))
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def define_model(args):
|
| 129 |
+
# 001 classical image sr
|
| 130 |
+
if args.task == 'classical_sr':
|
| 131 |
+
model = net(upscale=args.scale, in_chans=3, img_size=args.training_patch_size, window_size=8,
|
| 132 |
+
img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
|
| 133 |
+
mlp_ratio=2, upsampler='pixelshuffle', resi_connection='1conv')
|
| 134 |
+
param_key_g = 'params'
|
| 135 |
+
|
| 136 |
+
# 002 lightweight image sr
|
| 137 |
+
# use 'pixelshuffledirect' to save parameters
|
| 138 |
+
elif args.task == 'lightweight_sr':
|
| 139 |
+
model = net(upscale=args.scale, in_chans=3, img_size=64, window_size=8,
|
| 140 |
+
img_range=1., depths=[6, 6, 6, 6], embed_dim=60, num_heads=[6, 6, 6, 6],
|
| 141 |
+
mlp_ratio=2, upsampler='pixelshuffledirect', resi_connection='1conv')
|
| 142 |
+
param_key_g = 'params'
|
| 143 |
+
|
| 144 |
+
# 003 real-world image sr
|
| 145 |
+
elif args.task == 'real_sr':
|
| 146 |
+
if not args.large_model:
|
| 147 |
+
# use 'nearest+conv' to avoid block artifacts
|
| 148 |
+
model = net(upscale=args.scale, in_chans=3, img_size=64, window_size=8,
|
| 149 |
+
img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
|
| 150 |
+
mlp_ratio=2, upsampler='nearest+conv', resi_connection='1conv')
|
| 151 |
+
else:
|
| 152 |
+
# larger model size; use '3conv' to save parameters and memory; use ema for GAN training
|
| 153 |
+
model = net(upscale=args.scale, in_chans=3, img_size=64, window_size=8,
|
| 154 |
+
img_range=1., depths=[6, 6, 6, 6, 6, 6, 6, 6, 6], embed_dim=240,
|
| 155 |
+
num_heads=[8, 8, 8, 8, 8, 8, 8, 8, 8],
|
| 156 |
+
mlp_ratio=2, upsampler='nearest+conv', resi_connection='3conv')
|
| 157 |
+
param_key_g = 'params_ema'
|
| 158 |
+
|
| 159 |
+
# 004 grayscale image denoising
|
| 160 |
+
elif args.task == 'gray_dn':
|
| 161 |
+
model = net(upscale=1, in_chans=1, img_size=128, window_size=8,
|
| 162 |
+
img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
|
| 163 |
+
mlp_ratio=2, upsampler='', resi_connection='1conv')
|
| 164 |
+
param_key_g = 'params'
|
| 165 |
+
|
| 166 |
+
# 005 color image denoising
|
| 167 |
+
elif args.task == 'color_dn':
|
| 168 |
+
model = net(upscale=1, in_chans=3, img_size=128, window_size=8,
|
| 169 |
+
img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
|
| 170 |
+
mlp_ratio=2, upsampler='', resi_connection='1conv')
|
| 171 |
+
param_key_g = 'params'
|
| 172 |
+
|
| 173 |
+
# 006 grayscale JPEG compression artifact reduction
|
| 174 |
+
# use window_size=7 because JPEG encoding uses 8x8; use img_range=255 because it's sligtly better than 1
|
| 175 |
+
elif args.task == 'jpeg_car':
|
| 176 |
+
model = net(upscale=1, in_chans=1, img_size=126, window_size=7,
|
| 177 |
+
img_range=255., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
|
| 178 |
+
mlp_ratio=2, upsampler='', resi_connection='1conv')
|
| 179 |
+
param_key_g = 'params'
|
| 180 |
+
|
| 181 |
+
# 006 color JPEG compression artifact reduction
|
| 182 |
+
# use window_size=7 because JPEG encoding uses 8x8; use img_range=255 because it's sligtly better than 1
|
| 183 |
+
elif args.task == 'color_jpeg_car':
|
| 184 |
+
model = net(upscale=1, in_chans=3, img_size=126, window_size=7,
|
| 185 |
+
img_range=255., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
|
| 186 |
+
mlp_ratio=2, upsampler='', resi_connection='1conv')
|
| 187 |
+
param_key_g = 'params'
|
| 188 |
+
|
| 189 |
+
pretrained_model = torch.load(args.model_path)
|
| 190 |
+
model.load_state_dict(pretrained_model[param_key_g] if param_key_g in pretrained_model.keys() else pretrained_model, strict=True)
|
| 191 |
+
|
| 192 |
+
return model
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def setup(args):
|
| 196 |
+
# 001 classical image sr/ 002 lightweight image sr
|
| 197 |
+
if args.task in ['classical_sr', 'lightweight_sr']:
|
| 198 |
+
save_dir = f'results/swinir_{args.task}_x{args.scale}'
|
| 199 |
+
folder = args.folder_gt
|
| 200 |
+
border = args.scale
|
| 201 |
+
window_size = 8
|
| 202 |
+
|
| 203 |
+
# 003 real-world image sr
|
| 204 |
+
elif args.task in ['real_sr']:
|
| 205 |
+
save_dir = f'results/swinir_{args.task}_x{args.scale}'
|
| 206 |
+
if args.large_model:
|
| 207 |
+
save_dir += '_large'
|
| 208 |
+
folder = args.folder_lq
|
| 209 |
+
border = 0
|
| 210 |
+
window_size = 8
|
| 211 |
+
|
| 212 |
+
# 004 grayscale image denoising/ 005 color image denoising
|
| 213 |
+
elif args.task in ['gray_dn', 'color_dn']:
|
| 214 |
+
save_dir = f'results/swinir_{args.task}_noise{args.noise}'
|
| 215 |
+
folder = args.folder_gt
|
| 216 |
+
border = 0
|
| 217 |
+
window_size = 8
|
| 218 |
+
|
| 219 |
+
# 006 JPEG compression artifact reduction
|
| 220 |
+
elif args.task in ['jpeg_car', 'color_jpeg_car']:
|
| 221 |
+
save_dir = f'results/swinir_{args.task}_jpeg{args.jpeg}'
|
| 222 |
+
folder = args.folder_gt
|
| 223 |
+
border = 0
|
| 224 |
+
window_size = 7
|
| 225 |
+
|
| 226 |
+
return folder, save_dir, border, window_size
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def get_image_pair(args, path):
|
| 230 |
+
(imgname, imgext) = os.path.splitext(os.path.basename(path))
|
| 231 |
+
|
| 232 |
+
# 001 classical image sr/ 002 lightweight image sr (load lq-gt image pairs)
|
| 233 |
+
if args.task in ['classical_sr', 'lightweight_sr']:
|
| 234 |
+
img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
|
| 235 |
+
img_lq = cv2.imread(f'{args.folder_lq}/{imgname}x{args.scale}{imgext}', cv2.IMREAD_COLOR).astype(
|
| 236 |
+
np.float32) / 255.
|
| 237 |
+
|
| 238 |
+
# 003 real-world image sr (load lq image only)
|
| 239 |
+
elif args.task in ['real_sr']:
|
| 240 |
+
img_gt = None
|
| 241 |
+
img_lq = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
|
| 242 |
+
|
| 243 |
+
# 004 grayscale image denoising (load gt image and generate lq image on-the-fly)
|
| 244 |
+
elif args.task in ['gray_dn']:
|
| 245 |
+
img_gt = cv2.imread(path, cv2.IMREAD_GRAYSCALE).astype(np.float32) / 255.
|
| 246 |
+
np.random.seed(seed=0)
|
| 247 |
+
img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
|
| 248 |
+
img_gt = np.expand_dims(img_gt, axis=2)
|
| 249 |
+
img_lq = np.expand_dims(img_lq, axis=2)
|
| 250 |
+
|
| 251 |
+
# 005 color image denoising (load gt image and generate lq image on-the-fly)
|
| 252 |
+
elif args.task in ['color_dn']:
|
| 253 |
+
img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
|
| 254 |
+
np.random.seed(seed=0)
|
| 255 |
+
img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
|
| 256 |
+
|
| 257 |
+
# 006 grayscale JPEG compression artifact reduction (load gt image and generate lq image on-the-fly)
|
| 258 |
+
elif args.task in ['jpeg_car']:
|
| 259 |
+
img_gt = cv2.imread(path, cv2.IMREAD_UNCHANGED)
|
| 260 |
+
if img_gt.ndim != 2:
|
| 261 |
+
img_gt = util.bgr2ycbcr(img_gt, y_only=True)
|
| 262 |
+
result, encimg = cv2.imencode('.jpg', img_gt, [int(cv2.IMWRITE_JPEG_QUALITY), args.jpeg])
|
| 263 |
+
img_lq = cv2.imdecode(encimg, 0)
|
| 264 |
+
img_gt = np.expand_dims(img_gt, axis=2).astype(np.float32) / 255.
|
| 265 |
+
img_lq = np.expand_dims(img_lq, axis=2).astype(np.float32) / 255.
|
| 266 |
+
|
| 267 |
+
# 006 JPEG compression artifact reduction (load gt image and generate lq image on-the-fly)
|
| 268 |
+
elif args.task in ['color_jpeg_car']:
|
| 269 |
+
img_gt = cv2.imread(path)
|
| 270 |
+
result, encimg = cv2.imencode('.jpg', img_gt, [int(cv2.IMWRITE_JPEG_QUALITY), args.jpeg])
|
| 271 |
+
img_lq = cv2.imdecode(encimg, 1)
|
| 272 |
+
img_gt = img_gt.astype(np.float32)/ 255.
|
| 273 |
+
img_lq = img_lq.astype(np.float32)/ 255.
|
| 274 |
+
|
| 275 |
+
return imgname, img_lq, img_gt
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def test(img_lq, model, args, window_size):
|
| 279 |
+
if args.tile is None:
|
| 280 |
+
# test the image as a whole
|
| 281 |
+
output = model(img_lq)
|
| 282 |
+
else:
|
| 283 |
+
# test the image tile by tile
|
| 284 |
+
b, c, h, w = img_lq.size()
|
| 285 |
+
tile = min(args.tile, h, w)
|
| 286 |
+
assert tile % window_size == 0, "tile size should be a multiple of window_size"
|
| 287 |
+
tile_overlap = args.tile_overlap
|
| 288 |
+
sf = args.scale
|
| 289 |
+
|
| 290 |
+
stride = tile - tile_overlap
|
| 291 |
+
h_idx_list = list(range(0, h-tile, stride)) + [h-tile]
|
| 292 |
+
w_idx_list = list(range(0, w-tile, stride)) + [w-tile]
|
| 293 |
+
E = torch.zeros(b, c, h*sf, w*sf).type_as(img_lq)
|
| 294 |
+
W = torch.zeros_like(E)
|
| 295 |
+
|
| 296 |
+
for h_idx in h_idx_list:
|
| 297 |
+
for w_idx in w_idx_list:
|
| 298 |
+
in_patch = img_lq[..., h_idx:h_idx+tile, w_idx:w_idx+tile]
|
| 299 |
+
out_patch = model(in_patch)
|
| 300 |
+
out_patch_mask = torch.ones_like(out_patch)
|
| 301 |
+
|
| 302 |
+
E[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch)
|
| 303 |
+
W[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch_mask)
|
| 304 |
+
output = E.div_(W)
|
| 305 |
+
|
| 306 |
+
return output
|
| 307 |
+
|
| 308 |
+
if __name__ == '__main__':
|
| 309 |
+
main()
|
model_zoo/README.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_zoo
|
| 2 |
+
|
| 3 |
+
The SwinIR models are available at [here](https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0).
|
models/network_swinir.py
ADDED
|
@@ -0,0 +1,867 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -----------------------------------------------------------------------------------
|
| 2 |
+
# SwinIR: Image Restoration Using Swin Transformer, https://arxiv.org/abs/2108.10257
|
| 3 |
+
# Originally Written by Ze Liu, Modified by Jingyun Liang.
|
| 4 |
+
# -----------------------------------------------------------------------------------
|
| 5 |
+
|
| 6 |
+
import math
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torch.utils.checkpoint as checkpoint
|
| 11 |
+
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class Mlp(nn.Module):
|
| 15 |
+
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
|
| 16 |
+
super().__init__()
|
| 17 |
+
out_features = out_features or in_features
|
| 18 |
+
hidden_features = hidden_features or in_features
|
| 19 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 20 |
+
self.act = act_layer()
|
| 21 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 22 |
+
self.drop = nn.Dropout(drop)
|
| 23 |
+
|
| 24 |
+
def forward(self, x):
|
| 25 |
+
x = self.fc1(x)
|
| 26 |
+
x = self.act(x)
|
| 27 |
+
x = self.drop(x)
|
| 28 |
+
x = self.fc2(x)
|
| 29 |
+
x = self.drop(x)
|
| 30 |
+
return x
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def window_partition(x, window_size):
|
| 34 |
+
"""
|
| 35 |
+
Args:
|
| 36 |
+
x: (B, H, W, C)
|
| 37 |
+
window_size (int): window size
|
| 38 |
+
|
| 39 |
+
Returns:
|
| 40 |
+
windows: (num_windows*B, window_size, window_size, C)
|
| 41 |
+
"""
|
| 42 |
+
B, H, W, C = x.shape
|
| 43 |
+
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
|
| 44 |
+
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
|
| 45 |
+
return windows
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def window_reverse(windows, window_size, H, W):
|
| 49 |
+
"""
|
| 50 |
+
Args:
|
| 51 |
+
windows: (num_windows*B, window_size, window_size, C)
|
| 52 |
+
window_size (int): Window size
|
| 53 |
+
H (int): Height of image
|
| 54 |
+
W (int): Width of image
|
| 55 |
+
|
| 56 |
+
Returns:
|
| 57 |
+
x: (B, H, W, C)
|
| 58 |
+
"""
|
| 59 |
+
B = int(windows.shape[0] / (H * W / window_size / window_size))
|
| 60 |
+
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
|
| 61 |
+
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
|
| 62 |
+
return x
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class WindowAttention(nn.Module):
|
| 66 |
+
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
|
| 67 |
+
It supports both of shifted and non-shifted window.
|
| 68 |
+
|
| 69 |
+
Args:
|
| 70 |
+
dim (int): Number of input channels.
|
| 71 |
+
window_size (tuple[int]): The height and width of the window.
|
| 72 |
+
num_heads (int): Number of attention heads.
|
| 73 |
+
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 74 |
+
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
|
| 75 |
+
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
|
| 76 |
+
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
|
| 80 |
+
|
| 81 |
+
super().__init__()
|
| 82 |
+
self.dim = dim
|
| 83 |
+
self.window_size = window_size # Wh, Ww
|
| 84 |
+
self.num_heads = num_heads
|
| 85 |
+
head_dim = dim // num_heads
|
| 86 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 87 |
+
|
| 88 |
+
# define a parameter table of relative position bias
|
| 89 |
+
self.relative_position_bias_table = nn.Parameter(
|
| 90 |
+
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
|
| 91 |
+
|
| 92 |
+
# get pair-wise relative position index for each token inside the window
|
| 93 |
+
coords_h = torch.arange(self.window_size[0])
|
| 94 |
+
coords_w = torch.arange(self.window_size[1])
|
| 95 |
+
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
|
| 96 |
+
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
|
| 97 |
+
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
|
| 98 |
+
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
|
| 99 |
+
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
|
| 100 |
+
relative_coords[:, :, 1] += self.window_size[1] - 1
|
| 101 |
+
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
|
| 102 |
+
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
|
| 103 |
+
self.register_buffer("relative_position_index", relative_position_index)
|
| 104 |
+
|
| 105 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 106 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 107 |
+
self.proj = nn.Linear(dim, dim)
|
| 108 |
+
|
| 109 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 110 |
+
|
| 111 |
+
trunc_normal_(self.relative_position_bias_table, std=.02)
|
| 112 |
+
self.softmax = nn.Softmax(dim=-1)
|
| 113 |
+
|
| 114 |
+
def forward(self, x, mask=None):
|
| 115 |
+
"""
|
| 116 |
+
Args:
|
| 117 |
+
x: input features with shape of (num_windows*B, N, C)
|
| 118 |
+
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
|
| 119 |
+
"""
|
| 120 |
+
B_, N, C = x.shape
|
| 121 |
+
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 122 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
|
| 123 |
+
|
| 124 |
+
q = q * self.scale
|
| 125 |
+
attn = (q @ k.transpose(-2, -1))
|
| 126 |
+
|
| 127 |
+
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
|
| 128 |
+
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
|
| 129 |
+
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
|
| 130 |
+
attn = attn + relative_position_bias.unsqueeze(0)
|
| 131 |
+
|
| 132 |
+
if mask is not None:
|
| 133 |
+
nW = mask.shape[0]
|
| 134 |
+
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
|
| 135 |
+
attn = attn.view(-1, self.num_heads, N, N)
|
| 136 |
+
attn = self.softmax(attn)
|
| 137 |
+
else:
|
| 138 |
+
attn = self.softmax(attn)
|
| 139 |
+
|
| 140 |
+
attn = self.attn_drop(attn)
|
| 141 |
+
|
| 142 |
+
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
|
| 143 |
+
x = self.proj(x)
|
| 144 |
+
x = self.proj_drop(x)
|
| 145 |
+
return x
|
| 146 |
+
|
| 147 |
+
def extra_repr(self) -> str:
|
| 148 |
+
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
|
| 149 |
+
|
| 150 |
+
def flops(self, N):
|
| 151 |
+
# calculate flops for 1 window with token length of N
|
| 152 |
+
flops = 0
|
| 153 |
+
# qkv = self.qkv(x)
|
| 154 |
+
flops += N * self.dim * 3 * self.dim
|
| 155 |
+
# attn = (q @ k.transpose(-2, -1))
|
| 156 |
+
flops += self.num_heads * N * (self.dim // self.num_heads) * N
|
| 157 |
+
# x = (attn @ v)
|
| 158 |
+
flops += self.num_heads * N * N * (self.dim // self.num_heads)
|
| 159 |
+
# x = self.proj(x)
|
| 160 |
+
flops += N * self.dim * self.dim
|
| 161 |
+
return flops
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
class SwinTransformerBlock(nn.Module):
|
| 165 |
+
r""" Swin Transformer Block.
|
| 166 |
+
|
| 167 |
+
Args:
|
| 168 |
+
dim (int): Number of input channels.
|
| 169 |
+
input_resolution (tuple[int]): Input resulotion.
|
| 170 |
+
num_heads (int): Number of attention heads.
|
| 171 |
+
window_size (int): Window size.
|
| 172 |
+
shift_size (int): Shift size for SW-MSA.
|
| 173 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 174 |
+
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 175 |
+
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 176 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 177 |
+
attn_drop (float, optional): Attention dropout rate. Default: 0.0
|
| 178 |
+
drop_path (float, optional): Stochastic depth rate. Default: 0.0
|
| 179 |
+
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
|
| 180 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 181 |
+
"""
|
| 182 |
+
|
| 183 |
+
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
|
| 184 |
+
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
|
| 185 |
+
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
|
| 186 |
+
super().__init__()
|
| 187 |
+
self.dim = dim
|
| 188 |
+
self.input_resolution = input_resolution
|
| 189 |
+
self.num_heads = num_heads
|
| 190 |
+
self.window_size = window_size
|
| 191 |
+
self.shift_size = shift_size
|
| 192 |
+
self.mlp_ratio = mlp_ratio
|
| 193 |
+
if min(self.input_resolution) <= self.window_size:
|
| 194 |
+
# if window size is larger than input resolution, we don't partition windows
|
| 195 |
+
self.shift_size = 0
|
| 196 |
+
self.window_size = min(self.input_resolution)
|
| 197 |
+
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
|
| 198 |
+
|
| 199 |
+
self.norm1 = norm_layer(dim)
|
| 200 |
+
self.attn = WindowAttention(
|
| 201 |
+
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
|
| 202 |
+
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
|
| 203 |
+
|
| 204 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 205 |
+
self.norm2 = norm_layer(dim)
|
| 206 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 207 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
|
| 208 |
+
|
| 209 |
+
if self.shift_size > 0:
|
| 210 |
+
attn_mask = self.calculate_mask(self.input_resolution)
|
| 211 |
+
else:
|
| 212 |
+
attn_mask = None
|
| 213 |
+
|
| 214 |
+
self.register_buffer("attn_mask", attn_mask)
|
| 215 |
+
|
| 216 |
+
def calculate_mask(self, x_size):
|
| 217 |
+
# calculate attention mask for SW-MSA
|
| 218 |
+
H, W = x_size
|
| 219 |
+
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
|
| 220 |
+
h_slices = (slice(0, -self.window_size),
|
| 221 |
+
slice(-self.window_size, -self.shift_size),
|
| 222 |
+
slice(-self.shift_size, None))
|
| 223 |
+
w_slices = (slice(0, -self.window_size),
|
| 224 |
+
slice(-self.window_size, -self.shift_size),
|
| 225 |
+
slice(-self.shift_size, None))
|
| 226 |
+
cnt = 0
|
| 227 |
+
for h in h_slices:
|
| 228 |
+
for w in w_slices:
|
| 229 |
+
img_mask[:, h, w, :] = cnt
|
| 230 |
+
cnt += 1
|
| 231 |
+
|
| 232 |
+
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
|
| 233 |
+
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
|
| 234 |
+
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
|
| 235 |
+
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
|
| 236 |
+
|
| 237 |
+
return attn_mask
|
| 238 |
+
|
| 239 |
+
def forward(self, x, x_size):
|
| 240 |
+
H, W = x_size
|
| 241 |
+
B, L, C = x.shape
|
| 242 |
+
# assert L == H * W, "input feature has wrong size"
|
| 243 |
+
|
| 244 |
+
shortcut = x
|
| 245 |
+
x = self.norm1(x)
|
| 246 |
+
x = x.view(B, H, W, C)
|
| 247 |
+
|
| 248 |
+
# cyclic shift
|
| 249 |
+
if self.shift_size > 0:
|
| 250 |
+
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
|
| 251 |
+
else:
|
| 252 |
+
shifted_x = x
|
| 253 |
+
|
| 254 |
+
# partition windows
|
| 255 |
+
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
|
| 256 |
+
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
|
| 257 |
+
|
| 258 |
+
# W-MSA/SW-MSA (to be compatible for testing on images whose shapes are the multiple of window size
|
| 259 |
+
if self.input_resolution == x_size:
|
| 260 |
+
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
|
| 261 |
+
else:
|
| 262 |
+
attn_windows = self.attn(x_windows, mask=self.calculate_mask(x_size).to(x.device))
|
| 263 |
+
|
| 264 |
+
# merge windows
|
| 265 |
+
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
|
| 266 |
+
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
|
| 267 |
+
|
| 268 |
+
# reverse cyclic shift
|
| 269 |
+
if self.shift_size > 0:
|
| 270 |
+
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
|
| 271 |
+
else:
|
| 272 |
+
x = shifted_x
|
| 273 |
+
x = x.view(B, H * W, C)
|
| 274 |
+
|
| 275 |
+
# FFN
|
| 276 |
+
x = shortcut + self.drop_path(x)
|
| 277 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 278 |
+
|
| 279 |
+
return x
|
| 280 |
+
|
| 281 |
+
def extra_repr(self) -> str:
|
| 282 |
+
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
|
| 283 |
+
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
|
| 284 |
+
|
| 285 |
+
def flops(self):
|
| 286 |
+
flops = 0
|
| 287 |
+
H, W = self.input_resolution
|
| 288 |
+
# norm1
|
| 289 |
+
flops += self.dim * H * W
|
| 290 |
+
# W-MSA/SW-MSA
|
| 291 |
+
nW = H * W / self.window_size / self.window_size
|
| 292 |
+
flops += nW * self.attn.flops(self.window_size * self.window_size)
|
| 293 |
+
# mlp
|
| 294 |
+
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
|
| 295 |
+
# norm2
|
| 296 |
+
flops += self.dim * H * W
|
| 297 |
+
return flops
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
class PatchMerging(nn.Module):
|
| 301 |
+
r""" Patch Merging Layer.
|
| 302 |
+
|
| 303 |
+
Args:
|
| 304 |
+
input_resolution (tuple[int]): Resolution of input feature.
|
| 305 |
+
dim (int): Number of input channels.
|
| 306 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 307 |
+
"""
|
| 308 |
+
|
| 309 |
+
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
|
| 310 |
+
super().__init__()
|
| 311 |
+
self.input_resolution = input_resolution
|
| 312 |
+
self.dim = dim
|
| 313 |
+
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
|
| 314 |
+
self.norm = norm_layer(4 * dim)
|
| 315 |
+
|
| 316 |
+
def forward(self, x):
|
| 317 |
+
"""
|
| 318 |
+
x: B, H*W, C
|
| 319 |
+
"""
|
| 320 |
+
H, W = self.input_resolution
|
| 321 |
+
B, L, C = x.shape
|
| 322 |
+
assert L == H * W, "input feature has wrong size"
|
| 323 |
+
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
|
| 324 |
+
|
| 325 |
+
x = x.view(B, H, W, C)
|
| 326 |
+
|
| 327 |
+
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
|
| 328 |
+
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
|
| 329 |
+
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
|
| 330 |
+
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
|
| 331 |
+
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
|
| 332 |
+
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
|
| 333 |
+
|
| 334 |
+
x = self.norm(x)
|
| 335 |
+
x = self.reduction(x)
|
| 336 |
+
|
| 337 |
+
return x
|
| 338 |
+
|
| 339 |
+
def extra_repr(self) -> str:
|
| 340 |
+
return f"input_resolution={self.input_resolution}, dim={self.dim}"
|
| 341 |
+
|
| 342 |
+
def flops(self):
|
| 343 |
+
H, W = self.input_resolution
|
| 344 |
+
flops = H * W * self.dim
|
| 345 |
+
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
|
| 346 |
+
return flops
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
class BasicLayer(nn.Module):
|
| 350 |
+
""" A basic Swin Transformer layer for one stage.
|
| 351 |
+
|
| 352 |
+
Args:
|
| 353 |
+
dim (int): Number of input channels.
|
| 354 |
+
input_resolution (tuple[int]): Input resolution.
|
| 355 |
+
depth (int): Number of blocks.
|
| 356 |
+
num_heads (int): Number of attention heads.
|
| 357 |
+
window_size (int): Local window size.
|
| 358 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 359 |
+
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 360 |
+
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 361 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 362 |
+
attn_drop (float, optional): Attention dropout rate. Default: 0.0
|
| 363 |
+
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
|
| 364 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 365 |
+
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
|
| 366 |
+
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 367 |
+
"""
|
| 368 |
+
|
| 369 |
+
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
|
| 370 |
+
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
|
| 371 |
+
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
|
| 372 |
+
|
| 373 |
+
super().__init__()
|
| 374 |
+
self.dim = dim
|
| 375 |
+
self.input_resolution = input_resolution
|
| 376 |
+
self.depth = depth
|
| 377 |
+
self.use_checkpoint = use_checkpoint
|
| 378 |
+
|
| 379 |
+
# build blocks
|
| 380 |
+
self.blocks = nn.ModuleList([
|
| 381 |
+
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
|
| 382 |
+
num_heads=num_heads, window_size=window_size,
|
| 383 |
+
shift_size=0 if (i % 2 == 0) else window_size // 2,
|
| 384 |
+
mlp_ratio=mlp_ratio,
|
| 385 |
+
qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 386 |
+
drop=drop, attn_drop=attn_drop,
|
| 387 |
+
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
|
| 388 |
+
norm_layer=norm_layer)
|
| 389 |
+
for i in range(depth)])
|
| 390 |
+
|
| 391 |
+
# patch merging layer
|
| 392 |
+
if downsample is not None:
|
| 393 |
+
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
|
| 394 |
+
else:
|
| 395 |
+
self.downsample = None
|
| 396 |
+
|
| 397 |
+
def forward(self, x, x_size):
|
| 398 |
+
for blk in self.blocks:
|
| 399 |
+
if self.use_checkpoint:
|
| 400 |
+
x = checkpoint.checkpoint(blk, x, x_size)
|
| 401 |
+
else:
|
| 402 |
+
x = blk(x, x_size)
|
| 403 |
+
if self.downsample is not None:
|
| 404 |
+
x = self.downsample(x)
|
| 405 |
+
return x
|
| 406 |
+
|
| 407 |
+
def extra_repr(self) -> str:
|
| 408 |
+
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
|
| 409 |
+
|
| 410 |
+
def flops(self):
|
| 411 |
+
flops = 0
|
| 412 |
+
for blk in self.blocks:
|
| 413 |
+
flops += blk.flops()
|
| 414 |
+
if self.downsample is not None:
|
| 415 |
+
flops += self.downsample.flops()
|
| 416 |
+
return flops
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
class RSTB(nn.Module):
|
| 420 |
+
"""Residual Swin Transformer Block (RSTB).
|
| 421 |
+
|
| 422 |
+
Args:
|
| 423 |
+
dim (int): Number of input channels.
|
| 424 |
+
input_resolution (tuple[int]): Input resolution.
|
| 425 |
+
depth (int): Number of blocks.
|
| 426 |
+
num_heads (int): Number of attention heads.
|
| 427 |
+
window_size (int): Local window size.
|
| 428 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 429 |
+
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 430 |
+
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 431 |
+
drop (float, optional): Dropout rate. Default: 0.0
|
| 432 |
+
attn_drop (float, optional): Attention dropout rate. Default: 0.0
|
| 433 |
+
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
|
| 434 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 435 |
+
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
|
| 436 |
+
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 437 |
+
img_size: Input image size.
|
| 438 |
+
patch_size: Patch size.
|
| 439 |
+
resi_connection: The convolutional block before residual connection.
|
| 440 |
+
"""
|
| 441 |
+
|
| 442 |
+
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
|
| 443 |
+
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
|
| 444 |
+
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
|
| 445 |
+
img_size=224, patch_size=4, resi_connection='1conv'):
|
| 446 |
+
super(RSTB, self).__init__()
|
| 447 |
+
|
| 448 |
+
self.dim = dim
|
| 449 |
+
self.input_resolution = input_resolution
|
| 450 |
+
|
| 451 |
+
self.residual_group = BasicLayer(dim=dim,
|
| 452 |
+
input_resolution=input_resolution,
|
| 453 |
+
depth=depth,
|
| 454 |
+
num_heads=num_heads,
|
| 455 |
+
window_size=window_size,
|
| 456 |
+
mlp_ratio=mlp_ratio,
|
| 457 |
+
qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 458 |
+
drop=drop, attn_drop=attn_drop,
|
| 459 |
+
drop_path=drop_path,
|
| 460 |
+
norm_layer=norm_layer,
|
| 461 |
+
downsample=downsample,
|
| 462 |
+
use_checkpoint=use_checkpoint)
|
| 463 |
+
|
| 464 |
+
if resi_connection == '1conv':
|
| 465 |
+
self.conv = nn.Conv2d(dim, dim, 3, 1, 1)
|
| 466 |
+
elif resi_connection == '3conv':
|
| 467 |
+
# to save parameters and memory
|
| 468 |
+
self.conv = nn.Sequential(nn.Conv2d(dim, dim // 4, 3, 1, 1), nn.LeakyReLU(negative_slope=0.2, inplace=True),
|
| 469 |
+
nn.Conv2d(dim // 4, dim // 4, 1, 1, 0),
|
| 470 |
+
nn.LeakyReLU(negative_slope=0.2, inplace=True),
|
| 471 |
+
nn.Conv2d(dim // 4, dim, 3, 1, 1))
|
| 472 |
+
|
| 473 |
+
self.patch_embed = PatchEmbed(
|
| 474 |
+
img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,
|
| 475 |
+
norm_layer=None)
|
| 476 |
+
|
| 477 |
+
self.patch_unembed = PatchUnEmbed(
|
| 478 |
+
img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,
|
| 479 |
+
norm_layer=None)
|
| 480 |
+
|
| 481 |
+
def forward(self, x, x_size):
|
| 482 |
+
return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size), x_size))) + x
|
| 483 |
+
|
| 484 |
+
def flops(self):
|
| 485 |
+
flops = 0
|
| 486 |
+
flops += self.residual_group.flops()
|
| 487 |
+
H, W = self.input_resolution
|
| 488 |
+
flops += H * W * self.dim * self.dim * 9
|
| 489 |
+
flops += self.patch_embed.flops()
|
| 490 |
+
flops += self.patch_unembed.flops()
|
| 491 |
+
|
| 492 |
+
return flops
|
| 493 |
+
|
| 494 |
+
|
| 495 |
+
class PatchEmbed(nn.Module):
|
| 496 |
+
r""" Image to Patch Embedding
|
| 497 |
+
|
| 498 |
+
Args:
|
| 499 |
+
img_size (int): Image size. Default: 224.
|
| 500 |
+
patch_size (int): Patch token size. Default: 4.
|
| 501 |
+
in_chans (int): Number of input image channels. Default: 3.
|
| 502 |
+
embed_dim (int): Number of linear projection output channels. Default: 96.
|
| 503 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: None
|
| 504 |
+
"""
|
| 505 |
+
|
| 506 |
+
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
|
| 507 |
+
super().__init__()
|
| 508 |
+
img_size = to_2tuple(img_size)
|
| 509 |
+
patch_size = to_2tuple(patch_size)
|
| 510 |
+
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
|
| 511 |
+
self.img_size = img_size
|
| 512 |
+
self.patch_size = patch_size
|
| 513 |
+
self.patches_resolution = patches_resolution
|
| 514 |
+
self.num_patches = patches_resolution[0] * patches_resolution[1]
|
| 515 |
+
|
| 516 |
+
self.in_chans = in_chans
|
| 517 |
+
self.embed_dim = embed_dim
|
| 518 |
+
|
| 519 |
+
if norm_layer is not None:
|
| 520 |
+
self.norm = norm_layer(embed_dim)
|
| 521 |
+
else:
|
| 522 |
+
self.norm = None
|
| 523 |
+
|
| 524 |
+
def forward(self, x):
|
| 525 |
+
x = x.flatten(2).transpose(1, 2) # B Ph*Pw C
|
| 526 |
+
if self.norm is not None:
|
| 527 |
+
x = self.norm(x)
|
| 528 |
+
return x
|
| 529 |
+
|
| 530 |
+
def flops(self):
|
| 531 |
+
flops = 0
|
| 532 |
+
H, W = self.img_size
|
| 533 |
+
if self.norm is not None:
|
| 534 |
+
flops += H * W * self.embed_dim
|
| 535 |
+
return flops
|
| 536 |
+
|
| 537 |
+
|
| 538 |
+
class PatchUnEmbed(nn.Module):
|
| 539 |
+
r""" Image to Patch Unembedding
|
| 540 |
+
|
| 541 |
+
Args:
|
| 542 |
+
img_size (int): Image size. Default: 224.
|
| 543 |
+
patch_size (int): Patch token size. Default: 4.
|
| 544 |
+
in_chans (int): Number of input image channels. Default: 3.
|
| 545 |
+
embed_dim (int): Number of linear projection output channels. Default: 96.
|
| 546 |
+
norm_layer (nn.Module, optional): Normalization layer. Default: None
|
| 547 |
+
"""
|
| 548 |
+
|
| 549 |
+
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
|
| 550 |
+
super().__init__()
|
| 551 |
+
img_size = to_2tuple(img_size)
|
| 552 |
+
patch_size = to_2tuple(patch_size)
|
| 553 |
+
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
|
| 554 |
+
self.img_size = img_size
|
| 555 |
+
self.patch_size = patch_size
|
| 556 |
+
self.patches_resolution = patches_resolution
|
| 557 |
+
self.num_patches = patches_resolution[0] * patches_resolution[1]
|
| 558 |
+
|
| 559 |
+
self.in_chans = in_chans
|
| 560 |
+
self.embed_dim = embed_dim
|
| 561 |
+
|
| 562 |
+
def forward(self, x, x_size):
|
| 563 |
+
B, HW, C = x.shape
|
| 564 |
+
x = x.transpose(1, 2).view(B, self.embed_dim, x_size[0], x_size[1]) # B Ph*Pw C
|
| 565 |
+
return x
|
| 566 |
+
|
| 567 |
+
def flops(self):
|
| 568 |
+
flops = 0
|
| 569 |
+
return flops
|
| 570 |
+
|
| 571 |
+
|
| 572 |
+
class Upsample(nn.Sequential):
|
| 573 |
+
"""Upsample module.
|
| 574 |
+
|
| 575 |
+
Args:
|
| 576 |
+
scale (int): Scale factor. Supported scales: 2^n and 3.
|
| 577 |
+
num_feat (int): Channel number of intermediate features.
|
| 578 |
+
"""
|
| 579 |
+
|
| 580 |
+
def __init__(self, scale, num_feat):
|
| 581 |
+
m = []
|
| 582 |
+
if (scale & (scale - 1)) == 0: # scale = 2^n
|
| 583 |
+
for _ in range(int(math.log(scale, 2))):
|
| 584 |
+
m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
|
| 585 |
+
m.append(nn.PixelShuffle(2))
|
| 586 |
+
elif scale == 3:
|
| 587 |
+
m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
|
| 588 |
+
m.append(nn.PixelShuffle(3))
|
| 589 |
+
else:
|
| 590 |
+
raise ValueError(f'scale {scale} is not supported. ' 'Supported scales: 2^n and 3.')
|
| 591 |
+
super(Upsample, self).__init__(*m)
|
| 592 |
+
|
| 593 |
+
|
| 594 |
+
class UpsampleOneStep(nn.Sequential):
|
| 595 |
+
"""UpsampleOneStep module (the difference with Upsample is that it always only has 1conv + 1pixelshuffle)
|
| 596 |
+
Used in lightweight SR to save parameters.
|
| 597 |
+
|
| 598 |
+
Args:
|
| 599 |
+
scale (int): Scale factor. Supported scales: 2^n and 3.
|
| 600 |
+
num_feat (int): Channel number of intermediate features.
|
| 601 |
+
|
| 602 |
+
"""
|
| 603 |
+
|
| 604 |
+
def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
|
| 605 |
+
self.num_feat = num_feat
|
| 606 |
+
self.input_resolution = input_resolution
|
| 607 |
+
m = []
|
| 608 |
+
m.append(nn.Conv2d(num_feat, (scale ** 2) * num_out_ch, 3, 1, 1))
|
| 609 |
+
m.append(nn.PixelShuffle(scale))
|
| 610 |
+
super(UpsampleOneStep, self).__init__(*m)
|
| 611 |
+
|
| 612 |
+
def flops(self):
|
| 613 |
+
H, W = self.input_resolution
|
| 614 |
+
flops = H * W * self.num_feat * 3 * 9
|
| 615 |
+
return flops
|
| 616 |
+
|
| 617 |
+
|
| 618 |
+
class SwinIR(nn.Module):
|
| 619 |
+
r""" SwinIR
|
| 620 |
+
A PyTorch impl of : `SwinIR: Image Restoration Using Swin Transformer`, based on Swin Transformer.
|
| 621 |
+
|
| 622 |
+
Args:
|
| 623 |
+
img_size (int | tuple(int)): Input image size. Default 64
|
| 624 |
+
patch_size (int | tuple(int)): Patch size. Default: 1
|
| 625 |
+
in_chans (int): Number of input image channels. Default: 3
|
| 626 |
+
embed_dim (int): Patch embedding dimension. Default: 96
|
| 627 |
+
depths (tuple(int)): Depth of each Swin Transformer layer.
|
| 628 |
+
num_heads (tuple(int)): Number of attention heads in different layers.
|
| 629 |
+
window_size (int): Window size. Default: 7
|
| 630 |
+
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
|
| 631 |
+
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
|
| 632 |
+
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
|
| 633 |
+
drop_rate (float): Dropout rate. Default: 0
|
| 634 |
+
attn_drop_rate (float): Attention dropout rate. Default: 0
|
| 635 |
+
drop_path_rate (float): Stochastic depth rate. Default: 0.1
|
| 636 |
+
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
|
| 637 |
+
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
|
| 638 |
+
patch_norm (bool): If True, add normalization after patch embedding. Default: True
|
| 639 |
+
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
|
| 640 |
+
upscale: Upscale factor. 2/3/4/8 for image SR, 1 for denoising and compress artifact reduction
|
| 641 |
+
img_range: Image range. 1. or 255.
|
| 642 |
+
upsampler: The reconstruction reconstruction module. 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None
|
| 643 |
+
resi_connection: The convolutional block before residual connection. '1conv'/'3conv'
|
| 644 |
+
"""
|
| 645 |
+
|
| 646 |
+
def __init__(self, img_size=64, patch_size=1, in_chans=3,
|
| 647 |
+
embed_dim=96, depths=[6, 6, 6, 6], num_heads=[6, 6, 6, 6],
|
| 648 |
+
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
|
| 649 |
+
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
|
| 650 |
+
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
|
| 651 |
+
use_checkpoint=False, upscale=2, img_range=1., upsampler='', resi_connection='1conv',
|
| 652 |
+
**kwargs):
|
| 653 |
+
super(SwinIR, self).__init__()
|
| 654 |
+
num_in_ch = in_chans
|
| 655 |
+
num_out_ch = in_chans
|
| 656 |
+
num_feat = 64
|
| 657 |
+
self.img_range = img_range
|
| 658 |
+
if in_chans == 3:
|
| 659 |
+
rgb_mean = (0.4488, 0.4371, 0.4040)
|
| 660 |
+
self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
|
| 661 |
+
else:
|
| 662 |
+
self.mean = torch.zeros(1, 1, 1, 1)
|
| 663 |
+
self.upscale = upscale
|
| 664 |
+
self.upsampler = upsampler
|
| 665 |
+
self.window_size = window_size
|
| 666 |
+
|
| 667 |
+
#####################################################################################################
|
| 668 |
+
################################### 1, shallow feature extraction ###################################
|
| 669 |
+
self.conv_first = nn.Conv2d(num_in_ch, embed_dim, 3, 1, 1)
|
| 670 |
+
|
| 671 |
+
#####################################################################################################
|
| 672 |
+
################################### 2, deep feature extraction ######################################
|
| 673 |
+
self.num_layers = len(depths)
|
| 674 |
+
self.embed_dim = embed_dim
|
| 675 |
+
self.ape = ape
|
| 676 |
+
self.patch_norm = patch_norm
|
| 677 |
+
self.num_features = embed_dim
|
| 678 |
+
self.mlp_ratio = mlp_ratio
|
| 679 |
+
|
| 680 |
+
# split image into non-overlapping patches
|
| 681 |
+
self.patch_embed = PatchEmbed(
|
| 682 |
+
img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
|
| 683 |
+
norm_layer=norm_layer if self.patch_norm else None)
|
| 684 |
+
num_patches = self.patch_embed.num_patches
|
| 685 |
+
patches_resolution = self.patch_embed.patches_resolution
|
| 686 |
+
self.patches_resolution = patches_resolution
|
| 687 |
+
|
| 688 |
+
# merge non-overlapping patches into image
|
| 689 |
+
self.patch_unembed = PatchUnEmbed(
|
| 690 |
+
img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
|
| 691 |
+
norm_layer=norm_layer if self.patch_norm else None)
|
| 692 |
+
|
| 693 |
+
# absolute position embedding
|
| 694 |
+
if self.ape:
|
| 695 |
+
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
|
| 696 |
+
trunc_normal_(self.absolute_pos_embed, std=.02)
|
| 697 |
+
|
| 698 |
+
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 699 |
+
|
| 700 |
+
# stochastic depth
|
| 701 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
|
| 702 |
+
|
| 703 |
+
# build Residual Swin Transformer blocks (RSTB)
|
| 704 |
+
self.layers = nn.ModuleList()
|
| 705 |
+
for i_layer in range(self.num_layers):
|
| 706 |
+
layer = RSTB(dim=embed_dim,
|
| 707 |
+
input_resolution=(patches_resolution[0],
|
| 708 |
+
patches_resolution[1]),
|
| 709 |
+
depth=depths[i_layer],
|
| 710 |
+
num_heads=num_heads[i_layer],
|
| 711 |
+
window_size=window_size,
|
| 712 |
+
mlp_ratio=self.mlp_ratio,
|
| 713 |
+
qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 714 |
+
drop=drop_rate, attn_drop=attn_drop_rate,
|
| 715 |
+
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], # no impact on SR results
|
| 716 |
+
norm_layer=norm_layer,
|
| 717 |
+
downsample=None,
|
| 718 |
+
use_checkpoint=use_checkpoint,
|
| 719 |
+
img_size=img_size,
|
| 720 |
+
patch_size=patch_size,
|
| 721 |
+
resi_connection=resi_connection
|
| 722 |
+
|
| 723 |
+
)
|
| 724 |
+
self.layers.append(layer)
|
| 725 |
+
self.norm = norm_layer(self.num_features)
|
| 726 |
+
|
| 727 |
+
# build the last conv layer in deep feature extraction
|
| 728 |
+
if resi_connection == '1conv':
|
| 729 |
+
self.conv_after_body = nn.Conv2d(embed_dim, embed_dim, 3, 1, 1)
|
| 730 |
+
elif resi_connection == '3conv':
|
| 731 |
+
# to save parameters and memory
|
| 732 |
+
self.conv_after_body = nn.Sequential(nn.Conv2d(embed_dim, embed_dim // 4, 3, 1, 1),
|
| 733 |
+
nn.LeakyReLU(negative_slope=0.2, inplace=True),
|
| 734 |
+
nn.Conv2d(embed_dim // 4, embed_dim // 4, 1, 1, 0),
|
| 735 |
+
nn.LeakyReLU(negative_slope=0.2, inplace=True),
|
| 736 |
+
nn.Conv2d(embed_dim // 4, embed_dim, 3, 1, 1))
|
| 737 |
+
|
| 738 |
+
#####################################################################################################
|
| 739 |
+
################################ 3, high quality image reconstruction ################################
|
| 740 |
+
if self.upsampler == 'pixelshuffle':
|
| 741 |
+
# for classical SR
|
| 742 |
+
self.conv_before_upsample = nn.Sequential(nn.Conv2d(embed_dim, num_feat, 3, 1, 1),
|
| 743 |
+
nn.LeakyReLU(inplace=True))
|
| 744 |
+
self.upsample = Upsample(upscale, num_feat)
|
| 745 |
+
self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
|
| 746 |
+
elif self.upsampler == 'pixelshuffledirect':
|
| 747 |
+
# for lightweight SR (to save parameters)
|
| 748 |
+
self.upsample = UpsampleOneStep(upscale, embed_dim, num_out_ch,
|
| 749 |
+
(patches_resolution[0], patches_resolution[1]))
|
| 750 |
+
elif self.upsampler == 'nearest+conv':
|
| 751 |
+
# for real-world SR (less artifacts)
|
| 752 |
+
self.conv_before_upsample = nn.Sequential(nn.Conv2d(embed_dim, num_feat, 3, 1, 1),
|
| 753 |
+
nn.LeakyReLU(inplace=True))
|
| 754 |
+
self.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
|
| 755 |
+
if self.upscale == 4:
|
| 756 |
+
self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
|
| 757 |
+
self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
|
| 758 |
+
self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
|
| 759 |
+
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
|
| 760 |
+
else:
|
| 761 |
+
# for image denoising and JPEG compression artifact reduction
|
| 762 |
+
self.conv_last = nn.Conv2d(embed_dim, num_out_ch, 3, 1, 1)
|
| 763 |
+
|
| 764 |
+
self.apply(self._init_weights)
|
| 765 |
+
|
| 766 |
+
def _init_weights(self, m):
|
| 767 |
+
if isinstance(m, nn.Linear):
|
| 768 |
+
trunc_normal_(m.weight, std=.02)
|
| 769 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 770 |
+
nn.init.constant_(m.bias, 0)
|
| 771 |
+
elif isinstance(m, nn.LayerNorm):
|
| 772 |
+
nn.init.constant_(m.bias, 0)
|
| 773 |
+
nn.init.constant_(m.weight, 1.0)
|
| 774 |
+
|
| 775 |
+
@torch.jit.ignore
|
| 776 |
+
def no_weight_decay(self):
|
| 777 |
+
return {'absolute_pos_embed'}
|
| 778 |
+
|
| 779 |
+
@torch.jit.ignore
|
| 780 |
+
def no_weight_decay_keywords(self):
|
| 781 |
+
return {'relative_position_bias_table'}
|
| 782 |
+
|
| 783 |
+
def check_image_size(self, x):
|
| 784 |
+
_, _, h, w = x.size()
|
| 785 |
+
mod_pad_h = (self.window_size - h % self.window_size) % self.window_size
|
| 786 |
+
mod_pad_w = (self.window_size - w % self.window_size) % self.window_size
|
| 787 |
+
x = F.pad(x, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
|
| 788 |
+
return x
|
| 789 |
+
|
| 790 |
+
def forward_features(self, x):
|
| 791 |
+
x_size = (x.shape[2], x.shape[3])
|
| 792 |
+
x = self.patch_embed(x)
|
| 793 |
+
if self.ape:
|
| 794 |
+
x = x + self.absolute_pos_embed
|
| 795 |
+
x = self.pos_drop(x)
|
| 796 |
+
|
| 797 |
+
for layer in self.layers:
|
| 798 |
+
x = layer(x, x_size)
|
| 799 |
+
|
| 800 |
+
x = self.norm(x) # B L C
|
| 801 |
+
x = self.patch_unembed(x, x_size)
|
| 802 |
+
|
| 803 |
+
return x
|
| 804 |
+
|
| 805 |
+
def forward(self, x):
|
| 806 |
+
H, W = x.shape[2:]
|
| 807 |
+
x = self.check_image_size(x)
|
| 808 |
+
|
| 809 |
+
self.mean = self.mean.type_as(x)
|
| 810 |
+
x = (x - self.mean) * self.img_range
|
| 811 |
+
|
| 812 |
+
if self.upsampler == 'pixelshuffle':
|
| 813 |
+
# for classical SR
|
| 814 |
+
x = self.conv_first(x)
|
| 815 |
+
x = self.conv_after_body(self.forward_features(x)) + x
|
| 816 |
+
x = self.conv_before_upsample(x)
|
| 817 |
+
x = self.conv_last(self.upsample(x))
|
| 818 |
+
elif self.upsampler == 'pixelshuffledirect':
|
| 819 |
+
# for lightweight SR
|
| 820 |
+
x = self.conv_first(x)
|
| 821 |
+
x = self.conv_after_body(self.forward_features(x)) + x
|
| 822 |
+
x = self.upsample(x)
|
| 823 |
+
elif self.upsampler == 'nearest+conv':
|
| 824 |
+
# for real-world SR
|
| 825 |
+
x = self.conv_first(x)
|
| 826 |
+
x = self.conv_after_body(self.forward_features(x)) + x
|
| 827 |
+
x = self.conv_before_upsample(x)
|
| 828 |
+
x = self.lrelu(self.conv_up1(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
|
| 829 |
+
if self.upscale == 4:
|
| 830 |
+
x = self.lrelu(self.conv_up2(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
|
| 831 |
+
x = self.conv_last(self.lrelu(self.conv_hr(x)))
|
| 832 |
+
else:
|
| 833 |
+
# for image denoising and JPEG compression artifact reduction
|
| 834 |
+
x_first = self.conv_first(x)
|
| 835 |
+
res = self.conv_after_body(self.forward_features(x_first)) + x_first
|
| 836 |
+
x = x + self.conv_last(res)
|
| 837 |
+
|
| 838 |
+
x = x / self.img_range + self.mean
|
| 839 |
+
|
| 840 |
+
return x[:, :, :H*self.upscale, :W*self.upscale]
|
| 841 |
+
|
| 842 |
+
def flops(self):
|
| 843 |
+
flops = 0
|
| 844 |
+
H, W = self.patches_resolution
|
| 845 |
+
flops += H * W * 3 * self.embed_dim * 9
|
| 846 |
+
flops += self.patch_embed.flops()
|
| 847 |
+
for i, layer in enumerate(self.layers):
|
| 848 |
+
flops += layer.flops()
|
| 849 |
+
flops += H * W * 3 * self.embed_dim * self.embed_dim
|
| 850 |
+
flops += self.upsample.flops()
|
| 851 |
+
return flops
|
| 852 |
+
|
| 853 |
+
|
| 854 |
+
if __name__ == '__main__':
|
| 855 |
+
upscale = 4
|
| 856 |
+
window_size = 8
|
| 857 |
+
height = (1024 // upscale // window_size + 1) * window_size
|
| 858 |
+
width = (720 // upscale // window_size + 1) * window_size
|
| 859 |
+
model = SwinIR(upscale=2, img_size=(height, width),
|
| 860 |
+
window_size=window_size, img_range=1., depths=[6, 6, 6, 6],
|
| 861 |
+
embed_dim=60, num_heads=[6, 6, 6, 6], mlp_ratio=2, upsampler='pixelshuffledirect')
|
| 862 |
+
print(model)
|
| 863 |
+
print(height, width, model.flops() / 1e9)
|
| 864 |
+
|
| 865 |
+
x = torch.randn((1, 3, height, width))
|
| 866 |
+
x = model(x)
|
| 867 |
+
print(x.shape)
|
predict.py
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cog
|
| 2 |
+
import tempfile
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
import argparse
|
| 5 |
+
import shutil
|
| 6 |
+
import os
|
| 7 |
+
import cv2
|
| 8 |
+
import glob
|
| 9 |
+
import torch
|
| 10 |
+
from collections import OrderedDict
|
| 11 |
+
import numpy as np
|
| 12 |
+
from main_test_swinir import define_model, setup, get_image_pair
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Predictor(cog.Predictor):
|
| 16 |
+
def setup(self):
|
| 17 |
+
model_dir = 'experiments/pretrained_models'
|
| 18 |
+
|
| 19 |
+
self.model_zoo = {
|
| 20 |
+
'real_sr': {
|
| 21 |
+
4: os.path.join(model_dir, '003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth')
|
| 22 |
+
},
|
| 23 |
+
'gray_dn': {
|
| 24 |
+
15: os.path.join(model_dir, '004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth'),
|
| 25 |
+
25: os.path.join(model_dir, '004_grayDN_DFWB_s128w8_SwinIR-M_noise25.pth'),
|
| 26 |
+
50: os.path.join(model_dir, '004_grayDN_DFWB_s128w8_SwinIR-M_noise50.pth')
|
| 27 |
+
},
|
| 28 |
+
'color_dn': {
|
| 29 |
+
15: os.path.join(model_dir, '005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth'),
|
| 30 |
+
25: os.path.join(model_dir, '005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth'),
|
| 31 |
+
50: os.path.join(model_dir, '005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth')
|
| 32 |
+
},
|
| 33 |
+
'jpeg_car': {
|
| 34 |
+
10: os.path.join(model_dir, '006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth'),
|
| 35 |
+
20: os.path.join(model_dir, '006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth'),
|
| 36 |
+
30: os.path.join(model_dir, '006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth'),
|
| 37 |
+
40: os.path.join(model_dir, '006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth')
|
| 38 |
+
}
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
parser = argparse.ArgumentParser()
|
| 42 |
+
parser.add_argument('--task', type=str, default='real_sr', help='classical_sr, lightweight_sr, real_sr, '
|
| 43 |
+
'gray_dn, color_dn, jpeg_car')
|
| 44 |
+
parser.add_argument('--scale', type=int, default=1, help='scale factor: 1, 2, 3, 4, 8') # 1 for dn and jpeg car
|
| 45 |
+
parser.add_argument('--noise', type=int, default=15, help='noise level: 15, 25, 50')
|
| 46 |
+
parser.add_argument('--jpeg', type=int, default=40, help='scale factor: 10, 20, 30, 40')
|
| 47 |
+
parser.add_argument('--training_patch_size', type=int, default=128, help='patch size used in training SwinIR. '
|
| 48 |
+
'Just used to differentiate two different settings in Table 2 of the paper. '
|
| 49 |
+
'Images are NOT tested patch by patch.')
|
| 50 |
+
parser.add_argument('--large_model', action='store_true',
|
| 51 |
+
help='use large model, only provided for real image sr')
|
| 52 |
+
parser.add_argument('--model_path', type=str,
|
| 53 |
+
default=self.model_zoo['real_sr'][4])
|
| 54 |
+
parser.add_argument('--folder_lq', type=str, default=None, help='input low-quality test image folder')
|
| 55 |
+
parser.add_argument('--folder_gt', type=str, default=None, help='input ground-truth test image folder')
|
| 56 |
+
|
| 57 |
+
self.args = parser.parse_args('')
|
| 58 |
+
|
| 59 |
+
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 60 |
+
|
| 61 |
+
self.tasks = {
|
| 62 |
+
'Real-World Image Super-Resolution': 'real_sr',
|
| 63 |
+
'Grayscale Image Denoising': 'gray_dn',
|
| 64 |
+
'Color Image Denoising': 'color_dn',
|
| 65 |
+
'JPEG Compression Artifact Reduction': 'jpeg_car'
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
@cog.input("image", type=Path, help="input image")
|
| 69 |
+
@cog.input("task_type", type=str, default='Real-World Image Super-Resolution',
|
| 70 |
+
options=['Real-World Image Super-Resolution', 'Grayscale Image Denoising', 'Color Image Denoising',
|
| 71 |
+
'JPEG Compression Artifact Reduction'],
|
| 72 |
+
help="image restoration task type")
|
| 73 |
+
@cog.input("noise", type=int, default=15, options=[15, 25, 50],
|
| 74 |
+
help='noise level, activated for Grayscale Image Denoising and Color Image Denoising. '
|
| 75 |
+
'Leave it as default or arbitrary if other tasks are selected')
|
| 76 |
+
@cog.input("jpeg", type=int, default=40, options=[10, 20, 30, 40],
|
| 77 |
+
help='scale factor, activated for JPEG Compression Artifact Reduction. '
|
| 78 |
+
'Leave it as default or arbitrary if other tasks are selected')
|
| 79 |
+
def predict(self, image, task_type='Real-World Image Super-Resolution', jpeg=40, noise=15):
|
| 80 |
+
|
| 81 |
+
self.args.task = self.tasks[task_type]
|
| 82 |
+
self.args.noise = noise
|
| 83 |
+
self.args.jpeg = jpeg
|
| 84 |
+
|
| 85 |
+
# set model path
|
| 86 |
+
if self.args.task == 'real_sr':
|
| 87 |
+
self.args.scale = 4
|
| 88 |
+
self.args.model_path = self.model_zoo[self.args.task][4]
|
| 89 |
+
elif self.args.task in ['gray_dn', 'color_dn']:
|
| 90 |
+
self.args.model_path = self.model_zoo[self.args.task][noise]
|
| 91 |
+
else:
|
| 92 |
+
self.args.model_path = self.model_zoo[self.args.task][jpeg]
|
| 93 |
+
|
| 94 |
+
try:
|
| 95 |
+
# set input folder
|
| 96 |
+
input_dir = 'input_cog_temp'
|
| 97 |
+
os.makedirs(input_dir, exist_ok=True)
|
| 98 |
+
input_path = os.path.join(input_dir, os.path.basename(image))
|
| 99 |
+
shutil.copy(str(image), input_path)
|
| 100 |
+
if self.args.task == 'real_sr':
|
| 101 |
+
self.args.folder_lq = input_dir
|
| 102 |
+
else:
|
| 103 |
+
self.args.folder_gt = input_dir
|
| 104 |
+
|
| 105 |
+
model = define_model(self.args)
|
| 106 |
+
model.eval()
|
| 107 |
+
model = model.to(self.device)
|
| 108 |
+
|
| 109 |
+
# setup folder and path
|
| 110 |
+
folder, save_dir, border, window_size = setup(self.args)
|
| 111 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 112 |
+
test_results = OrderedDict()
|
| 113 |
+
test_results['psnr'] = []
|
| 114 |
+
test_results['ssim'] = []
|
| 115 |
+
test_results['psnr_y'] = []
|
| 116 |
+
test_results['ssim_y'] = []
|
| 117 |
+
test_results['psnr_b'] = []
|
| 118 |
+
# psnr, ssim, psnr_y, ssim_y, psnr_b = 0, 0, 0, 0, 0
|
| 119 |
+
out_path = Path(tempfile.mkdtemp()) / "out.png"
|
| 120 |
+
|
| 121 |
+
for idx, path in enumerate(sorted(glob.glob(os.path.join(folder, '*')))):
|
| 122 |
+
# read image
|
| 123 |
+
imgname, img_lq, img_gt = get_image_pair(self.args, path) # image to HWC-BGR, float32
|
| 124 |
+
img_lq = np.transpose(img_lq if img_lq.shape[2] == 1 else img_lq[:, :, [2, 1, 0]],
|
| 125 |
+
(2, 0, 1)) # HCW-BGR to CHW-RGB
|
| 126 |
+
img_lq = torch.from_numpy(img_lq).float().unsqueeze(0).to(self.device) # CHW-RGB to NCHW-RGB
|
| 127 |
+
|
| 128 |
+
# inference
|
| 129 |
+
with torch.no_grad():
|
| 130 |
+
# pad input image to be a multiple of window_size
|
| 131 |
+
_, _, h_old, w_old = img_lq.size()
|
| 132 |
+
h_pad = (h_old // window_size + 1) * window_size - h_old
|
| 133 |
+
w_pad = (w_old // window_size + 1) * window_size - w_old
|
| 134 |
+
img_lq = torch.cat([img_lq, torch.flip(img_lq, [2])], 2)[:, :, :h_old + h_pad, :]
|
| 135 |
+
img_lq = torch.cat([img_lq, torch.flip(img_lq, [3])], 3)[:, :, :, :w_old + w_pad]
|
| 136 |
+
output = model(img_lq)
|
| 137 |
+
output = output[..., :h_old * self.args.scale, :w_old * self.args.scale]
|
| 138 |
+
|
| 139 |
+
# save image
|
| 140 |
+
output = output.data.squeeze().float().cpu().clamp_(0, 1).numpy()
|
| 141 |
+
if output.ndim == 3:
|
| 142 |
+
output = np.transpose(output[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
|
| 143 |
+
output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
|
| 144 |
+
cv2.imwrite(str(out_path), output)
|
| 145 |
+
finally:
|
| 146 |
+
clean_folder(input_dir)
|
| 147 |
+
return out_path
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def clean_folder(folder):
|
| 151 |
+
for filename in os.listdir(folder):
|
| 152 |
+
file_path = os.path.join(folder, filename)
|
| 153 |
+
try:
|
| 154 |
+
if os.path.isfile(file_path) or os.path.islink(file_path):
|
| 155 |
+
os.unlink(file_path)
|
| 156 |
+
elif os.path.isdir(file_path):
|
| 157 |
+
shutil.rmtree(file_path)
|
| 158 |
+
except Exception as e:
|
| 159 |
+
print('Failed to delete %s. Reason: %s' % (file_path, e))
|
testsets/McMaster/1.tif
ADDED
|
|
testsets/McMaster/10.tif
ADDED
|
|
testsets/McMaster/11.tif
ADDED
|
|
testsets/McMaster/12.tif
ADDED
|
|
testsets/McMaster/13.tif
ADDED
|
|
testsets/McMaster/14.tif
ADDED
|
|
testsets/McMaster/15.tif
ADDED
|
|
testsets/McMaster/16.tif
ADDED
|
|
testsets/McMaster/17.tif
ADDED
|
|
testsets/McMaster/18.tif
ADDED
|
|
testsets/McMaster/2.tif
ADDED
|
|
testsets/McMaster/3.tif
ADDED
|
|
testsets/McMaster/4.tif
ADDED
|
|
testsets/McMaster/5.tif
ADDED
|
|
testsets/McMaster/6.tif
ADDED
|
|
testsets/McMaster/7.tif
ADDED
|
|
testsets/McMaster/8.tif
ADDED
|
|
testsets/McMaster/9.tif
ADDED
|
|
testsets/RealSRSet+5images/00003.png
ADDED

|
testsets/RealSRSet+5images/0014.jpg
ADDED

|
testsets/RealSRSet+5images/0030.jpg
ADDED

|
testsets/RealSRSet+5images/ADE_val_00000114.jpg
ADDED

|
testsets/RealSRSet+5images/Lincoln.png
ADDED

|