

Update README.md
Browse files
README.md
CHANGED
|
@@ -8,71 +8,99 @@ pinned: false
|
|
| 8 |
---
|
| 9 |
|
| 10 |
|
| 11 |
-
# Audio
|
| 12 |
|
| 13 |
-
This is an ensemble of
|
| 14 |
-
Both models are trained independently, and their prediction has been averaged.
|
| 15 |
|
| 16 |
-
|
|
|
|
|
|
|
| 17 |
|
| 18 |
-
- **Primary intended
|
| 19 |
|
|
|
|
| 20 |
|
| 21 |
## Training Data
|
| 22 |
|
| 23 |
-
The model uses the rfcx/frugalai dataset:
|
| 24 |
-
- Size
|
| 25 |
-
- Split
|
| 26 |
-
- Binary labels
|
|
|
|
|
|
|
|
|
|
|
|
|
| 27 |
|
| 28 |
-
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
-
|
| 31 |
-
A few files have a bigger sampling rate, so we resample them at 12000. For audios that are smaller than 3 seconds, we add a reverse padding at the end.
|
| 32 |
-
Raw audio data are stored in a numpy array of size (n, 36000), with float 16 precision to gain in memory usage (there is no drop in precision compared to float 32).
|
| 33 |
|
| 34 |
-
## Model Description
|
| 35 |
-
This is an XGBoost Regressor, with probability in output, composed of 3000 trees.
|
| 36 |
|
| 37 |
-
|
| 38 |
|
| 39 |
-
|
| 40 |
-
- **MFCC** : 55 mfcc are retains. A window size of 1024 is used for nfft. I took the mean and standard deviation along the spatial axis (110 features)
|
| 41 |
-
- **Mel Spectrogram** : The mel spectrogram is calculated with a window size of 1024 for nfft, and 55 mel.
|
| 42 |
-
I took the mean and standard deviation along the spatial axis (110 features). In addition, I added the standard deviation of the delta coefficient of the spectrogram,
|
| 43 |
-
in order to capture the caracteristic signature of the chainsaw sound, when it goes from idle to full load (55 more features).
|
| 44 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |
### Training Details
|
| 47 |
-
I used the python library xgboost. I trained the model using cuda, with a learning rate of 0.02. No data augmentation were used.
|
| 48 |
-
The notebook used for the training : [notebook](/spaces/kangourous/submission-audio-task/blob/main/notebooks/XGBoost_train.ipynb)
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
-
## Model Description
|
| 52 |
-
This is an CNN, with a sigmoid activation, of almost 1M parameters.
|
| 53 |
|
| 54 |
-
|
| 55 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
|
| 57 |
### Training Details
|
| 58 |
-
Pytorch was used to trained this model, with an Adam Optimizer with a learning rate of 0.001, a Binary Cross Entropy Loss. I randomly added sound labeled
|
| 59 |
-
as environnement, to add more noise to the dataset, without changing the labels.
|
| 60 |
|
| 61 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
## Performance
|
| 65 |
-
|
| 66 |
-
|
| 67 |
|
| 68 |
### Metrics
|
| 69 |
-
- **XGBoost Accuracy**: ~95.3%
|
| 70 |
-
- **CNN Accuracy**: ~95.7%
|
| 71 |
-
- **Total Accuracy**: ~96.1%
|
| 72 |
-
- **Total Energy consumption in Wh (on nvidia T4)**: ~0.164
|
| 73 |
|
| 74 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 75 |
|
|
|
|
| 76 |
|
| 77 |
## Environmental Impact
|
| 78 |
|
|
|
|
| 8 |
---
|
| 9 |
|
| 10 |
|
| 11 |
+
# Audio Classification - XGBoost and Small Deep Neural Network
|
| 12 |
|
| 13 |
+
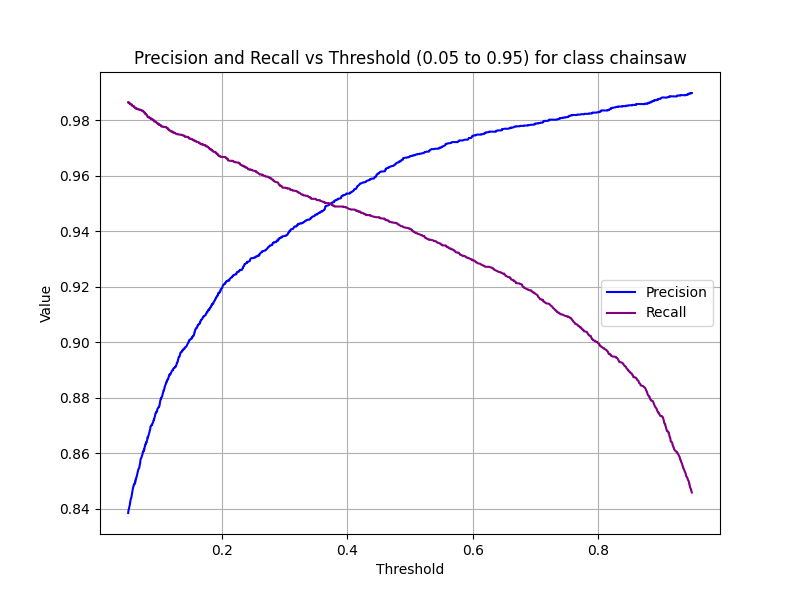
This is an ensemble of two models (XGBoost and a small CNN) for the audio classification task of the Frugal AI Challenge 2024. Instead of providing binary labels (0 or 1), both models predict a probability between 0 and 1. This allows a trade-off between precision and recall by setting a threshold within this range. Both models are trained independently, and their predictions are averaged.
|
|
|
|
| 14 |
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
## Intended Use
|
| 18 |
|
| 19 |
+
- **Primary intended use**: Identifying illegal logging in forests.
|
| 20 |
|
| 21 |
+
---
|
| 22 |
|
| 23 |
## Training Data
|
| 24 |
|
| 25 |
+
The model uses the `rfcx/frugalai` dataset:
|
| 26 |
+
- **Size**: ~50,000 examples.
|
| 27 |
+
- **Split**: 70% training, 30% testing.
|
| 28 |
+
- **Binary labels**:
|
| 29 |
+
- `0`: Chainsaw.
|
| 30 |
+
- `1`: Environment.
|
| 31 |
+
|
| 32 |
+
### Data Preprocessing
|
| 33 |
|
| 34 |
+
Most audio samples are 3 seconds long, with a sampling rate of 12,000 Hz. This means each row of the dataset contains 36,000 elements.
|
| 35 |
+
- **Resampling**: Audio files with a higher sampling rate are downsampled to 12,000 Hz.
|
| 36 |
+
- **Padding**: Audio files shorter than 3 seconds are padded with their reversed signal at the end.
|
| 37 |
+
- **Storage**: Raw audio data is stored in a NumPy array of size `(n, 36,000)` with `float16` precision to reduce memory usage without significant precision loss compared to `float32`.
|
| 38 |
|
| 39 |
+
---
|
|
|
|
|
|
|
| 40 |
|
| 41 |
+
## Model Description: XGBoost
|
|
|
|
| 42 |
|
| 43 |
+
This is an XGBoost regressor that outputs probabilities. It consists of 3,000 trees.
|
| 44 |
|
| 45 |
+
### Input Features
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
|
| 47 |
+
XGBoost uses the following input features:
|
| 48 |
+
- **MFCC**:
|
| 49 |
+
- 55 MFCCs are retained.
|
| 50 |
+
- Calculated with a window size of 1,024 for `nfft`.
|
| 51 |
+
- Mean and standard deviation are taken along the spatial axis (resulting in 110 features).
|
| 52 |
+
- **Mel Spectrogram**:
|
| 53 |
+
- Calculated with a window size of 1,024 for `nfft` and 55 mel bands.
|
| 54 |
+
- Mean and standard deviation along the spatial axis (110 features).
|
| 55 |
+
- Standard deviation of the delta coefficients of the spectrogram (55 additional features). This captures the characteristic signature of chainsaw sounds transitioning from idle to full load.
|
| 56 |
+
- (See [Exploratory Data Analysis](/spaces/kangourous/submission-audio-task/blob/main/notebooks/EDA.ipynb))
|
| 57 |
|
| 58 |
### Training Details
|
|
|
|
|
|
|
| 59 |
|
| 60 |
+
- Framework: Python library `xgboost`.
|
| 61 |
+
- Training on GPU using CUDA.
|
| 62 |
+
- Learning rate: `0.02`.
|
| 63 |
+
- No data augmentation was used.
|
| 64 |
+
|
| 65 |
+
**Training notebook**: [XGBoost Training Notebook](/spaces/kangourous/submission-audio-task/blob/main/notebooks/XGBoost_train.ipynb)
|
| 66 |
+
|
| 67 |
+
---
|
| 68 |
|
| 69 |
+
## Model Description: CNN
|
|
|
|
| 70 |
|
| 71 |
+
This is a small convolutional neural network (CNN) with sigmoid activation and approximately 1M parameters.
|
| 72 |
+
|
| 73 |
+
### Input Features
|
| 74 |
+
|
| 75 |
+
The CNN uses **Log Mel Spectrograms** as input features:
|
| 76 |
+
- Calculated with a window size of 1,024 for `nfft` and 100 mel bands.
|
| 77 |
|
| 78 |
### Training Details
|
|
|
|
|
|
|
| 79 |
|
| 80 |
+
- Framework: PyTorch.
|
| 81 |
+
- Optimizer: Adam.
|
| 82 |
+
- Learning rate: `0.001`.
|
| 83 |
+
- Loss function: Binary Cross-Entropy Loss.
|
| 84 |
+
- Data augmentation: Additional environment-labeled sounds were added to increase dataset noise without modifying the labels.
|
| 85 |
|
| 86 |
+
**Training notebook**: [CNN Training Notebook](/spaces/kangourous/submission-audio-task/blob/main/notebooks/CNN_training.ipynb)
|
| 87 |
+
|
| 88 |
+
---
|
| 89 |
|
| 90 |
## Performance
|
| 91 |
+
|
| 92 |
+
In this challenge, accuracy and energy consumption are measured. The generation of spectrograms, MFCCs, and model inference are included in the energy consumption tracking. However, data loading is not included.
|
| 93 |
|
| 94 |
### Metrics
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
|
| 96 |
+
- **XGBoost Accuracy**: ~95.3%
|
| 97 |
+
- **CNN Accuracy**: ~95.7%
|
| 98 |
+
- **Ensemble Accuracy**: ~96.1%
|
| 99 |
+
- **Total Energy Consumption (in Wh, on NVIDIA T4)**: ~0.164
|
| 100 |
+
|
| 101 |
+
|
| 102 |
|
| 103 |
+
---
|
| 104 |
|
| 105 |
## Environmental Impact
|
| 106 |
|