
Current Training Steps: 100,000
This repo contains a low-rank adapter (LoRA) for LLaMA-7b fit on the Stanford-Alpaca-52k and databricks-dolly-15k data in 52 languages.
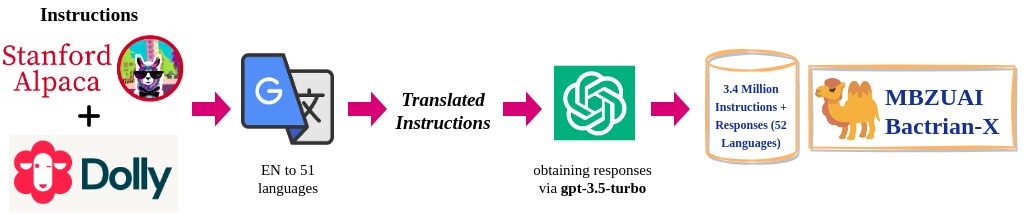
Dataset Creation
- English Instructions: The English instuctions are obtained from alpaca-52k, and dolly-15k.
- Instruction Translation: The instructions (and inputs) are translated into the target languages using Google Translation API (conducted on April 2023).
- Output Generation: We generate output from
gpt-3.5-turbofor each language (conducted on April 2023).
Training Parameters
The code for training the model is provided in our github, which is adapted from Alpaca-LoRA. This version of the weights was trained with the following hyperparameters:
- Epochs: 10
- Batch size: 128
- Cutoff length: 512
- Learning rate: 3e-4
- Lora r: 64
- Lora target modules: q_proj, k_proj, v_proj, o_proj
That is:
python finetune.py \
--base_model='decapoda-research/llama-7b-hf' \
--num_epochs=10 \
--batch_size=128 \
--cutoff_len=512 \
--group_by_length \
--output_dir='./bactrian-x-llama-7b-lora' \
--lora_target_modules='q_proj,k_proj,v_proj,o_proj' \
--lora_r=64 \
--micro_batch_size=32
Instructions for running it can be found at https://github.com/MBZUAI-nlp/Bactrian-X.
Discussion of Biases
(1) Translation bias; (2) Potential English-culture bias in the translated dataset.
Citation Information
@misc{li2023bactrianx,
title={Bactrian-X : A Multilingual Replicable Instruction-Following Model with Low-Rank Adaptation},
author={Haonan Li and Fajri Koto and Minghao Wu and Alham Fikri Aji and Timothy Baldwin},
year={2023},
eprint={2305.15011},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support