
NE-BERT: Northeast India's Multilingual ModernBERT
NE-BERT is a state-of-the-art transformer model designed specifically for the complex, low-resource linguistic landscape of Northeast India. It achieves strong Regional State-of-the-Art (SOTA) performance across multiple Northeast Indian languages and 2x to 3x faster inference compared to general multilingual models.
Built on the ModernBERT architecture, it supports a context length of 1024 tokens, utilizes Flash Attention 2 for high-efficiency inference, and treats Northeast languages as first-class citizens.
Quick Start
NE-BERT is built on the ModernBERT architecture. You must use transformers>=4.48.0.
# First, install the library:
# pip install -U transformers
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
# Load NE-BERT (No remote code needed for transformers >= 4.48)
model_name = "MWirelabs/ne-bert"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForMaskedLM.from_pretrained(model_name)
# Example: Nagamese Creole (ISO: nag)
text = "Moi bhat <mask>." # "I [eat] rice"
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# Retrieve top prediction
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
print(tokenizer.decode(predicted_token_id))
# Output: "khai" (eat)
Training Data & Strategy
NE-BERT was trained on a meticulously curated corpus using a Smart-Weighted Sampling strategy to ensure the low-resource languages were not drowned out by anchor languages.

| Language | HF Tag | Script | Corpus Size | Training Strategy |
|---|---|---|---|---|
| Assamese | asm-Beng |
Bengali-Assamese | ~1M Sentences | Native |
| Meitei (Manipuri) | mni-Beng |
Bengali-Assamese | ~1.3M Sentences | Native |
| Khasi | kha-Latn |
Roman | ~1M Sentences | Native |
| Mizo | lus-Latn |
Roman | ~1M Sentences | Native |
| Nyishi | njz-Latn |
Roman | ~55k Sentences | Oversampled (20x) |
| Nagamese | nag-Latn |
Roman | ~13k Sentences | Oversampled (20x) |
| Garo | grt-Latn |
Roman | ~10k Sentences | Oversampled (20x) |
| Pnar | pbv-Latn |
Roman | ~1k Sentences | Oversampled (100x) |
| Kokborok | trp-Latn |
Roman | ~2.5k Sentences | Oversampled (100x) |
| Anchor Languages | eng-Latn/hin-Deva |
Roman/Devanagari | ~660k Sentences | Downsampled |
Note on Oversampling
To address the extreme data imbalance (e.g., 1k Pnar sentences vs 3M Hindi sentences), we applied aggressive upsampling to micro-languages. To prevent overfitting on these repeated examples, we utilized Dynamic Masking during training. This ensures that the model sees different masking patterns for the same sentence across epochs, forcing it to learn semantic relationships rather than memorizing token sequences.
Evaluation and Benchmarks: Regional SOTA
We evaluated NE-BERT against industry-standard multilingual models (mBERT and IndicBERT) on a final, complex, held-out test set to ensure reproducibility and rigor.
1. The "Eye Test": Qualitative Comparison
The superiority of NE-BERT is evident when predicting missing words in low-resource languages. While generic models predict punctuation or sub-word fragments, NE-BERT predicts coherent, culturally relevant words.
| Language | Input Sentence | NE-BERT (Ours) | mBERT | IndicBERT |
|---|---|---|---|---|
| Assamese | মই ভাত <mask> ভাল পাওঁ। (I like to [eat] rice) |
খাই (Eat) Correct Verb |
##ি Fragment |
, Punctuation |
| Khasi | Nga leit sha <mask>. (I go to [home/market]) |
iing (Home) Correct Noun |
. Period |
s Character |
| Garo | Anga <mask> cha·jok. (I [ate] ...) |
nokni (Of house) Real Word |
- Symbol |
. Period |
2. Effectiveness: Perplexity (PPL)
Perplexity measures the model's fluency and understanding of text (lower is better). This comparison proves NE-BERT's superior language modeling across the board, particularly in low-resource settings.
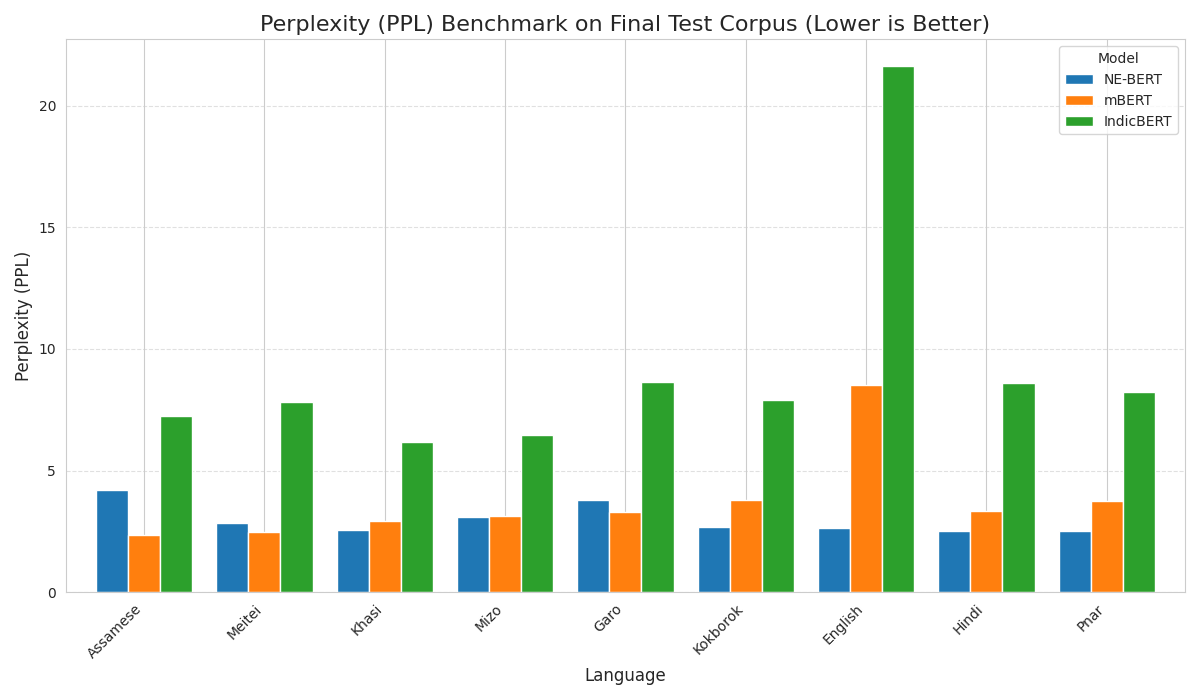
| Language | NE-BERT | mBERT | IndicBERT | Verdict |
|---|---|---|---|---|
Pnar (pbv) |
2.51 | 3.74 | 8.25 | 3x Better than IndicBERT |
Khasi (kha) |
2.58 | 2.94 | 6.16 | Best Specialized Model |
Kokborok (trp) |
2.67 | 3.79 | 7.91 | Strong SOTA |
Assamese (asm) |
4.19 | 2.34 | 7.26 | Competitive |
Mizo (lus) |
3.09 | 3.13 | 6.45 | Best Specialized Model |
Garo (grt) |
3.80 | 3.32 | 8.64 | Crushes IndicBERT |
3. Efficiency: Token Fertility (Inference Speed)
Token Fertility (Tokens per Word) is the key metric for inference speed and memory footprint (lower is better). NE-BERT's custom Unigram tokenizer delivers massive efficiency gains.

Result: NE-BERT is 2x to 3x more token-efficient on major languages than mBERT and IndicBERT, translating directly to faster inference and lower VRAM consumption in production.
Training Performance

- Final Training Loss: 1.62
- Final Validation Loss: 1.64
- Convergence: The model achieved optimal convergence where validation loss tracked closely with training loss, indicating robust generalization despite the small dataset size of rare languages.
Technical Specifications
- Architecture: ModernBERT-Base (Pre-Norm, Rotary Embeddings)
- Parameters: ~149 Million
- Context Window: 1024 Tokens
- Tokenizer: Custom Unigram SentencePiece (Vocab: 50,368)
- Training Hardware: NVIDIA A40 (48GB)
- Training Duration: 10 Epochs
Limitations and Bias
While NE-BERT significantly outperforms existing models on these languages, users should be aware:
- Meitei/Hindi Leakage: Due to the shared script and the high volume of Hindi anchor data, the model may sometimes predict Hindi/Sanskrit words (e.g., "Narayan") in Meitei contexts if the sentence structure is ambiguous.
- Domain Specificity: The model is trained largely on general web text. It may struggle with highly technical or poetic domains in micro-languages due to limited data size.
Citation
If you use this model in your research, please cite:
@misc{ne-bert-2025,
author = {MWirelabs},
title = {NE-BERT: A Multilingual ModernBERT for Northeast India},
year = {2025},
publisher = {Hugging Face},
journal = {Hugging Face Model Hub},
howpublished = {\url{[https://huggingface.co/MWirelabs/ne-bert](https://huggingface.co/MWirelabs/ne-bert)}}
}
- Downloads last month
- 107
Space using MWirelabs/ne-bert 1
Evaluation results
- Perplexity on NE-BERT Evaluation Corpusself-reported2.981