
TNSA's NGen 3 Series of Models
Collection
TNSA AI's NGen 3 Model Squad
•
14 items
•
Updated
•
1
The information you provide will be collected, stored, processed and shared in accordance with the TNSA Privacy Policy.
Log in or Sign Up to review the conditions and access this model content.
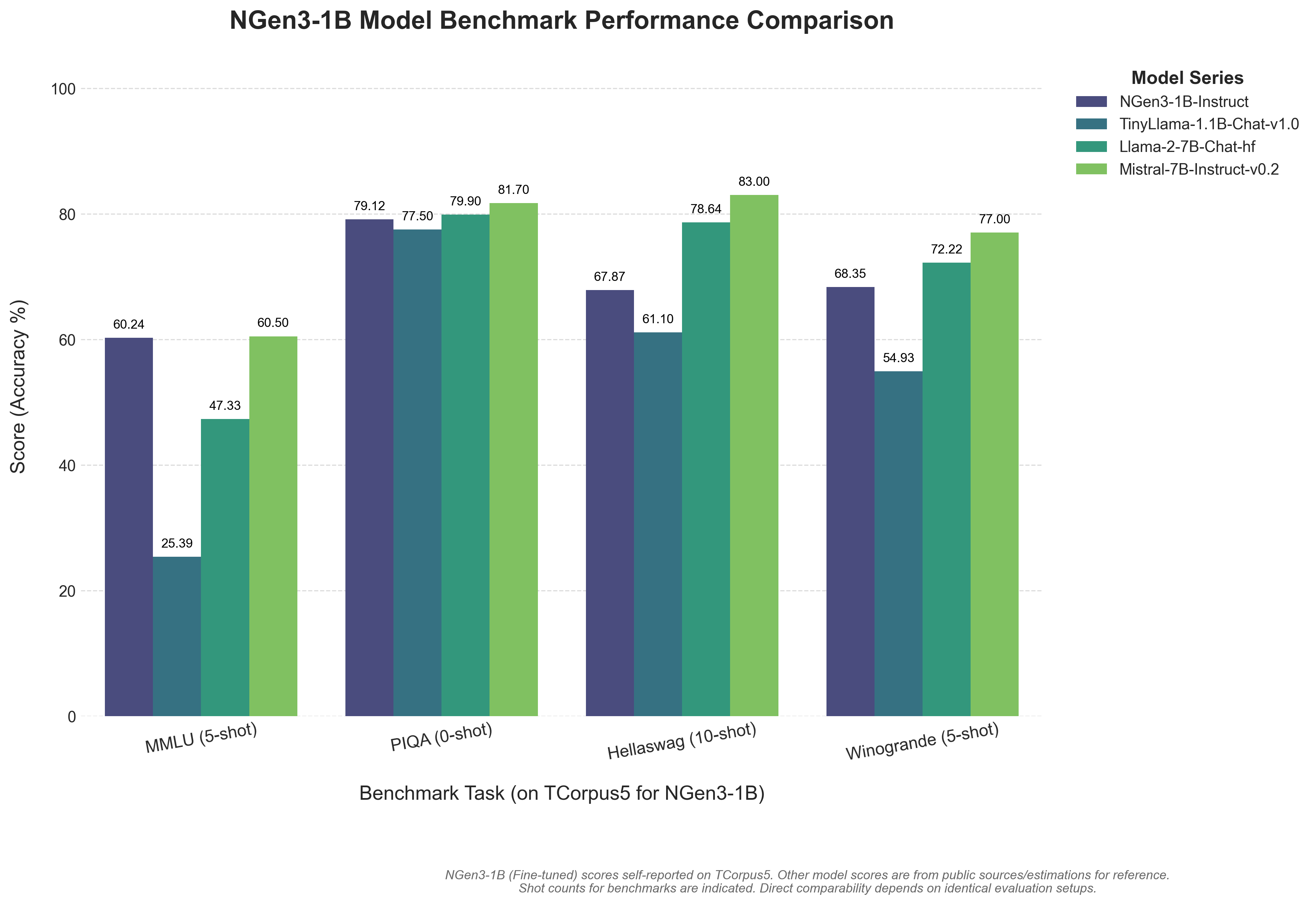
NGen3 is a production-level foundational language model inspired by state-of-the-art architectures such as GPT-4, Claude-3, and Llama 2. It is designed for both research and production and supports model variants ranging from 7M to 1B parameters. The model is built with a modular transformer decoder architecture and provides a comprehensive command-line interface (CLI) for tokenization, training, sampling, exporting, knowledge distillation, and fine-tuning on conversational data.
.png)
NGen3 is a flexible, self-contained implementation of a foundational language model built on a transformer decoder architecture. It enables users to:
NGen3 uses a decoder-only transformer design with the following components:
The model comes in several variants:
Ensure you have Python 3.8+ installed and install the necessary dependencies:
pip install torch transformers datasets tqdm safetensors
NGen3 is fully managed via a CLI. Below are examples for each command. Tokenization Local Text File or URL:
python _model_.py tokenize --dataset tinyshakespeare --txt "https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt"
Hugging Face Dataset:
python _model_.py hf_tokenize --hf_dataset roskoN/dailydialog --hf_split train --hf_text_column utterances --dataset dailydialog_train
Train a model variant (e.g., 7M):
python _model_.py train --variant 7M --data _data_tinyshakespeare_/data.bin
Generate text samples from a trained model:
python _model_.py sample --variant 7M --model_checkpoint 7M_model.pt --prompt "To be, or not to be" --length 100 --temperature 1.0
Export a trained model (and its tokenizer configuration) for Hugging Face:
python _model_.py export --variant 7M --model_path 7M_model.pt --output_dir exported_7M
Distill a larger teacher model (e.g., GPT-2 120M from HF) into a smaller student model (e.g., 7M):
python _model_.py distill --teacher_model_path hf --teacher_variant 120M --student_variant 7M --data _data_tinyshakespeare_/data.bin --temperature 2.0 --alpha 0.5
Local Fine-Tuning on Conversational Data Fine-tune a distilled model using local conversation data:
python _model_.py finetune --variant 120M --model_checkpoint distilled_120M_model.pt --data _data_conversations_/data.bin --finetune_iters 1000 --prompt "Hello, how are you?" --sample_length 100 --sample_temperature 1.0
Hugging Face Fine-Tuning on a Conversational Dataset Fine-tune on a conversational dataset from Hugging Face (e.g., roskoN/dailydialog):
python _model_.py hf_finetune --variant 120M --model_checkpoint distilled_120M_model.pt --hf_dataset roskoN/dailydialog --hf_split train --hf_text_column utterances --finetune_iters 1000 --prompt "Hello, how are you?" --sample_length 100 --sample_temperature 1.0
After fine-tuning, you can sample from or export the fine-tuned model just as with any checkpoint. For example, if your fine-tuned model is saved as finetuned_120M_model.pt:
Sampling:
python _model_.py sample --variant 120M --model_checkpoint finetuned_120M_model.pt --prompt "What do you think about AI?" --length 100 --temperature 1.0
Exporting:
python _model_.py export --variant 120M --model_path finetuned_120M_model.pt --output_dir exported_finetuned_120M
Each model variant comes with predefined hyperparameters. For example:
7M Variant:
Layers: 4, Heads: 4, Embedding Dimension: 128 Block Size: 128, Batch Size: 16, Learning Rate: 3e-4 120M Variant:
Layers: 12, Heads: 8, Embedding Dimension: 512 Block Size: 256, Batch Size: 32, Learning Rate: 3e-4 300M, 500M, 700M, 1B Variants: Increasing layers, heads, and embedding dimensions for better performance.
Adjust max_iters, log_interval, and eval_interval to suit your dataset size and computational resources.
NGen3 is inspired by leading models including GPT-4, Claude-3, and Llama 2. Special thanks to the open-source community for:
Base model
TNSA/NGen3-1B