a smol course documentation
Entendiendo ORPO
Optimización por Ratios de Probabilidad de Preferencias (ORPO)
ORPO (Odds Ratio Preference Optimization) es una técnica novedosa de fine-tuning que combina el fine-tuning y la alineación de preferencias en un único proceso unificado. Este enfoque combinado ofrece ventajas en términos de eficiencia y rendimiento en comparación con métodos tradicionales como RLHF o DPO.
Entendiendo ORPO
Los métodos de alineación como DPO suelen involucrar dos pasos separados: fine-tuning supervisado para adaptar el modelo a un dominio y formato, seguido de la alineación de preferencias para alinearse con las preferencias humanas. Mientras que el fine-tuning fino supervisado (SFT) adapta eficazmente los modelos a los dominios objetivo, puede aumentar inadvertidamente la probabilidad de generar tanto respuestas deseables como indeseables. ORPO aborda esta limitación integrando ambos pasos en un solo proceso, como se ilustra en la siguiente comparación:
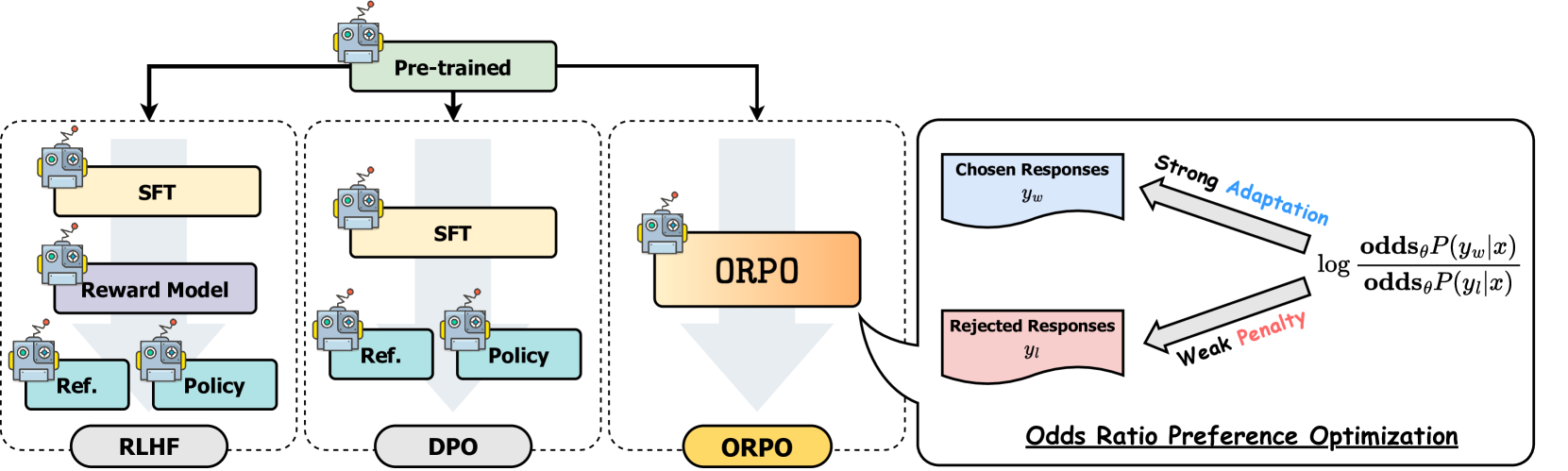 Comparación de diferentes técnicas de alineación de modelos
Comparación de diferentes técnicas de alineación de modelos
Cómo Funciona ORPO
El proceso de entrenamiento de ORPO utiliza un conjunto de datos de preferencias similar al que usamos para DPO, donde cada ejemplo de entrenamiento contiene un prompt de entrada junto con dos respuestas: una preferida y otra rechazada. A diferencia de otros métodos de alineación que requieren etapas separadas y modelos de referencia, ORPO integra la alineación de preferencias directamente en el proceso de fine-tuning supervisado. Este enfoque monolítico lo hace libre de modelos de referencia, computacionalmente más eficiente y eficiente en memoria, con menos FLOPs.
ORPO crea un nuevo objetivo combinando dos componentes principales:
Pérdida de SFT: La pérdida estándar de log-verosimilitud negativa utilizada en la modelización de lenguaje, que maximiza la probabilidad de generar tokens de referencia. Esto ayuda a mantener las capacidades generales del modelo en lenguaje.
Pérdida de Odds Ratio: Un componente novedoso que penaliza respuestas no deseadas mientras recompensa las preferidas. Esta función de pérdida utiliza odds ratios para contrastar eficazmente entre respuestas favorecidas y desfavorecidas a nivel de token.
Juntos, estos componentes guían al modelo para adaptarse a las generaciones deseadas para el dominio específico mientras desalienta activamente las generaciones del conjunto de respuestas rechazadas. El mecanismo de odds ratio proporciona una manera natural de medir y optimizar las preferencias del modelo entre respuestas elegidas y rechazadas. Si deseas profundizar en las matemáticas, puedes leer el artículo de ORPO. Si deseas aprender sobre ORPO desde la perspectiva de implementación, puedes revisar cómo se calcula la pérdida de ORPO en la biblioteca TRL.
Rendimiento y Resultados
ORPO ha demostrado resultados impresionantes en varios puntos de referencia. En MT-Bench, alcanza puntuaciones competitivas en diferentes categorías:
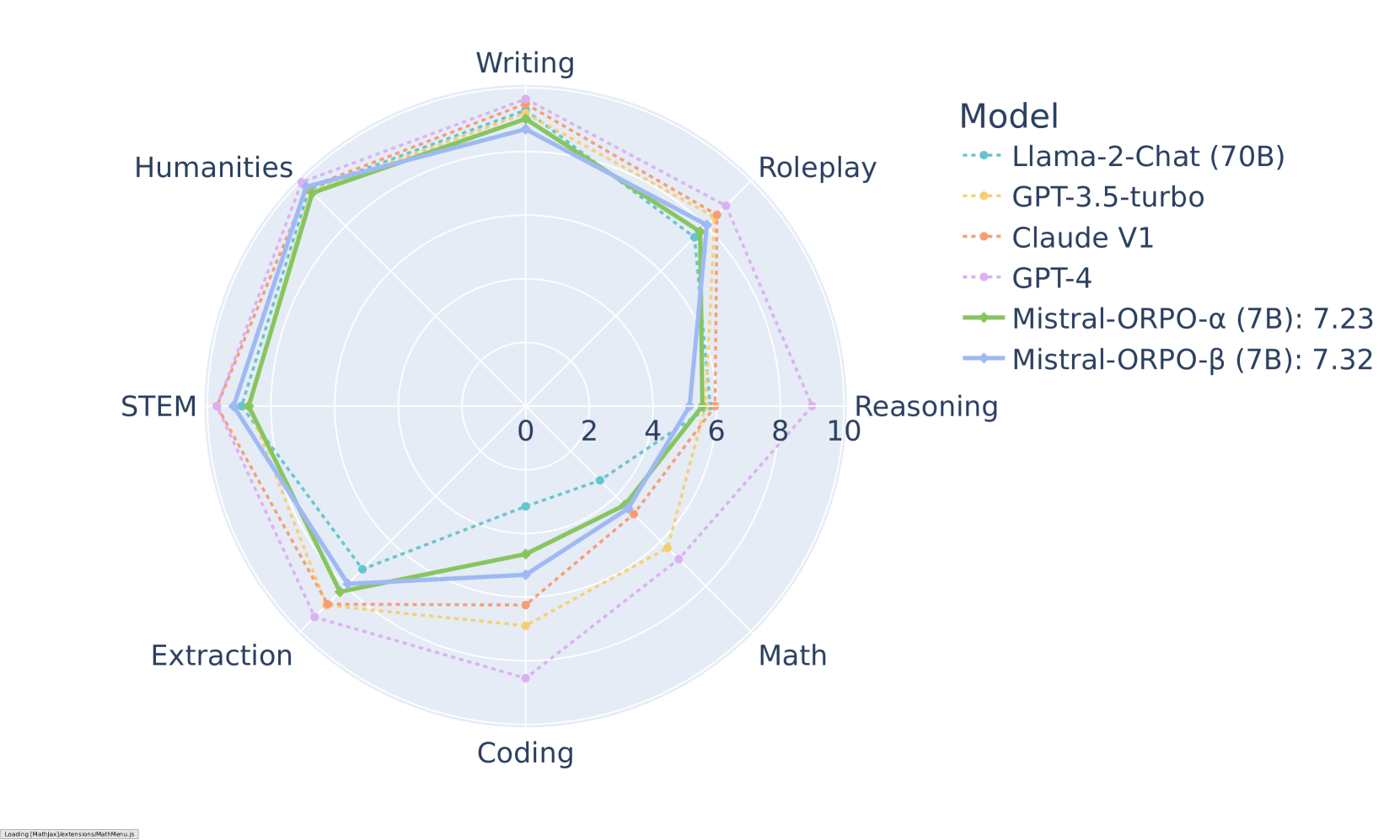 Resultados de MT-Bench por categoría para modelos Mistral-ORPO
Resultados de MT-Bench por categoría para modelos Mistral-ORPO
Cuando se compara con otros métodos de alineación, ORPO muestra un rendimiento superior en AlpacaEval 2.0:
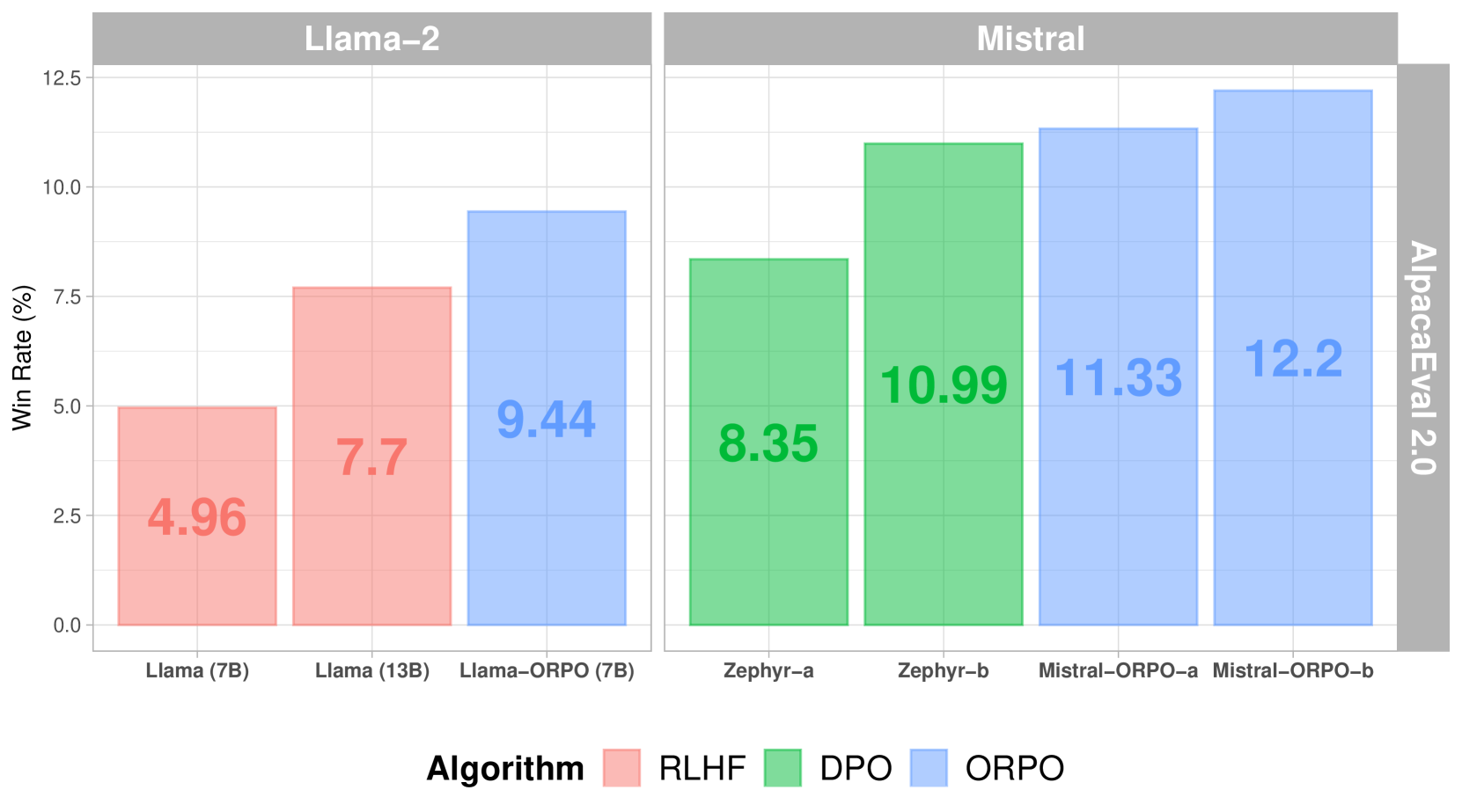 Puntuaciones de AlpacaEval 2.0 en diferentes métodos de alineación
Puntuaciones de AlpacaEval 2.0 en diferentes métodos de alineación
En comparación con SFT+DPO, ORPO reduce los requisitos computacionales al eliminar la necesidad de un modelo de referencia y reducir a la mitad el número de pasadas hacia adelante por lote. Además, el proceso de entrenamiento es más estable en diferentes tamaños de modelos y conjuntos de datos, lo que requiere menos hiperparámetros para ajustar. En cuanto al rendimiento, ORPO iguala a modelos más grandes mientras muestra una mejor alineación con las preferencias humanas.
Implementación
La implementación exitosa de ORPO depende en gran medida de datos de preferencias de alta calidad. Los datos de entrenamiento deben seguir pautas claras de anotación y proporcionar una representación equilibrada de respuestas preferidas y rechazadas en diversos escenarios.
Implementación con TRL
ORPO se puede implementar utilizando la biblioteca Transformers Reinforcement Learning (TRL). Aquí tienes un ejemplo básico:
from trl import ORPOConfig, ORPOTrainer
<CopyLLMTxtMenu containerStyle="float: right; margin-left: 10px; display: inline-flex; position: relative; z-index: 10;"></CopyLLMTxtMenu>
# Configurar el entrenamiento de ORPO
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # Controla la fuerza de la optimización de preferencias
orpo_beta=0.1, # Parámetro de temperatura para el cálculo de odds ratio
)
# Inicializar el entrenador
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# Iniciar el entrenamiento
trainer.train()Parámetros clave a considerar:
orpo_alpha: Controla la fuerza de la optimización de preferenciasorpo_beta: Parámetro de temperatura para el cálculo de odds ratiolearning_rate: Debe ser relativamente pequeño para evitar el olvido catastróficogradient_accumulation_steps: Ayuda con la estabilidad del entrenamiento
Próximos Pasos
⏩ Prueba el Tutorial de ORPO para implementar este enfoque unificado de alineación de preferencias.