a smol course documentation
ORPOの理解
選好確率比最適化(ORPO)
ORPOの理解
DPOのような選好整合方法は、通常、微調整と選好整合の2つの別々のステップを含みます。微調整はモデルを特定のドメインや形式に適応させ、選好整合は人間の選好に合わせて出力を調整します。SFT(教師あり微調整)は、モデルをターゲットドメインに適応させるのに効果的ですが、望ましい応答と望ましくない応答の両方の確率を増加させる可能性があります。ORPOは、以下の比較図に示すように、これらのステップを単一のプロセスに統合することで、この制限に対処します。
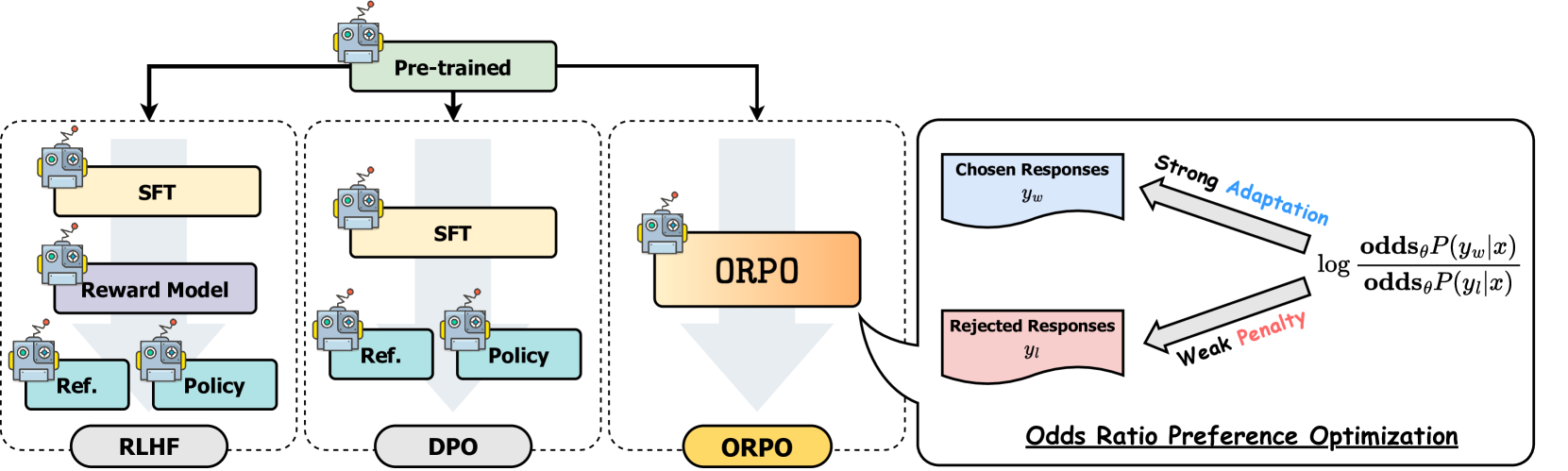 モデル整合技術の比較
モデル整合技術の比較
ORPOの仕組み
ORPOのトレーニングプロセスは、DPOと同様に、入力プロンプトと2つの応答(1つは選好、もう1つは非選好)を含む選好データセットを使用します。他の整合方法とは異なり、ORPOは選好整合を教師あり微調整プロセスに直接統合します。この統合アプローチにより、参照モデルが不要になり、計算効率とメモリ効率が向上し、FLOP数が減少します。
ORPOは、次の2つの主要なコンポーネントを組み合わせて新しい目的を作成します:
- SFT損失:負の対数尤度損失を使用して、参照トークンの生成確率を最大化します。これにより、モデルの一般的な言語能力が維持されます。
- オッズ比損失:望ましくない応答をペナルティし、選好される応答を報酬する新しいコンポーネントです。この損失関数は、トークンレベルで選好される応答と非選好の応答を効果的に対比するためにオッズ比を使用します。
これらのコンポーネントを組み合わせることで、モデルは特定のドメインに対して望ましい生成を適応させながら、非選好の応答を積極的に抑制します。オッズ比メカニズムは、選好された応答と拒否された応答の間のモデルの選好を測定および最適化する自然な方法を提供します。数学的な詳細については、ORPO論文を参照してください。実装の観点からORPOについて学びたい場合は、TRLライブラリでORPO損失がどのように計算されるかを確認してください。
パフォーマンスと結果
ORPOは、さまざまなベンチマークで印象的な結果を示しています。MT-Benchでは、さまざまなカテゴリで競争力のあるスコアを達成しています:
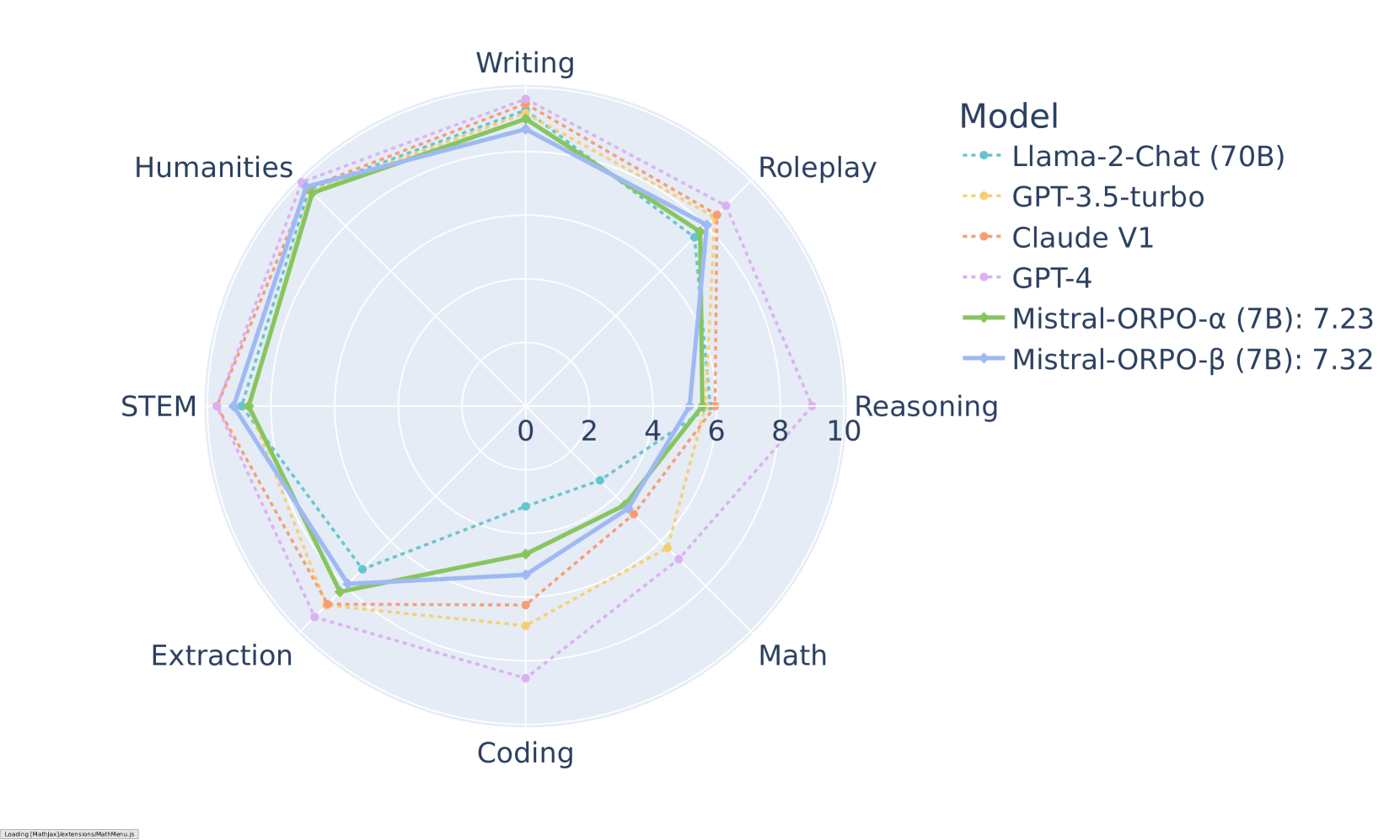 MT-Benchのカテゴリ別結果(Mistral-ORPOモデル)
MT-Benchのカテゴリ別結果(Mistral-ORPOモデル)
他の整合方法と比較すると、ORPOはAlpacaEval 2.0で優れたパフォーマンスを示しています:
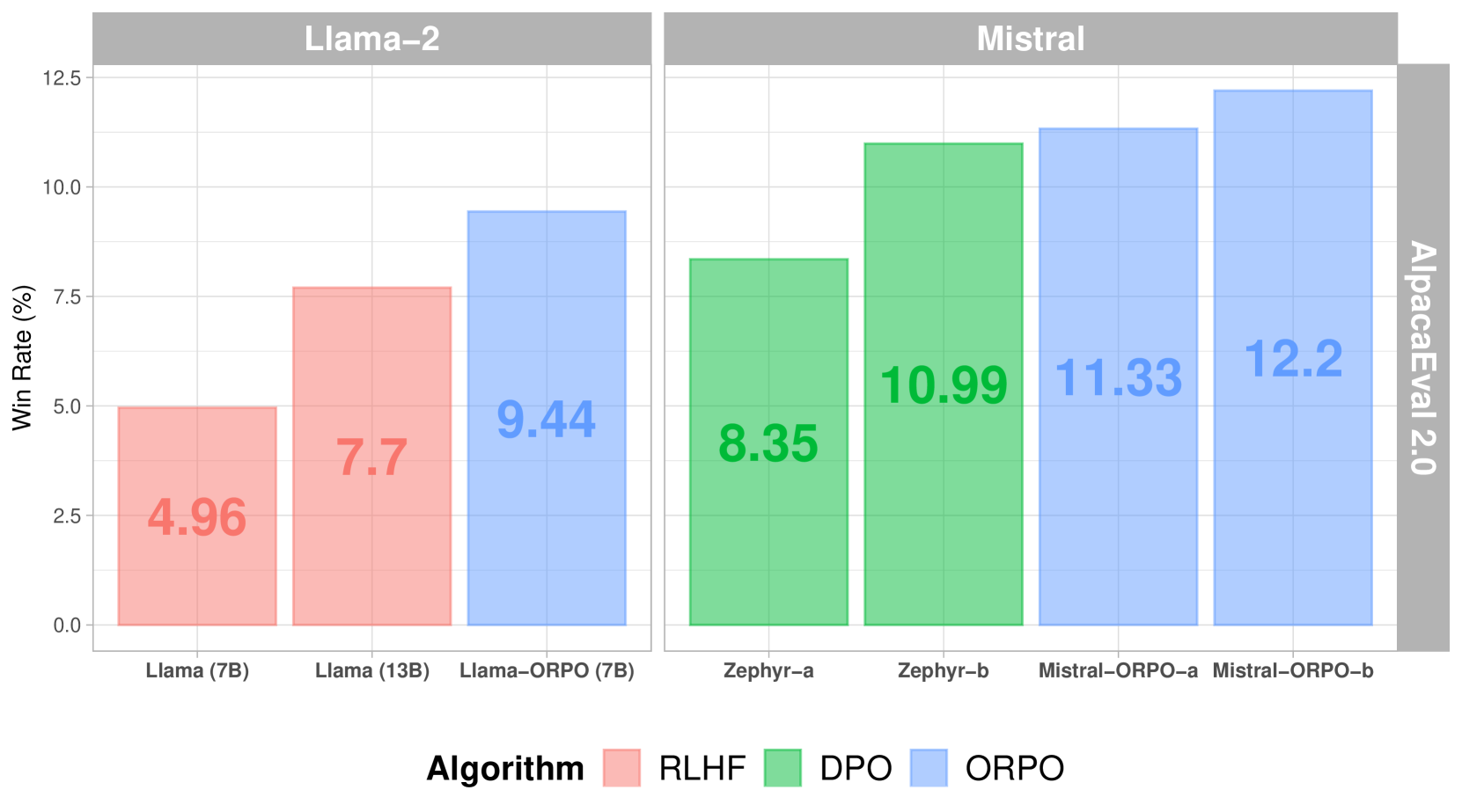 さまざまな整合方法におけるAlpacaEval 2.0スコア
さまざまな整合方法におけるAlpacaEval 2.0スコア
SFT+DPOと比較して、ORPOは参照モデルが不要であり、バッチごとのフォワードパスの数を半減させることで計算要件を削減します。さらに、トレーニングプロセスは、さまざまなモデルサイズとデータセットでより安定しており、調整するハイパーパラメータが少なくて済みます。パフォーマンスに関しては、ORPOはより大きなモデルと同等のパフォーマンスを示しながら、人間の選好に対する整合性が向上しています。
実装
ORPOの成功した実装は、高品質の選好データに大きく依存します。トレーニングデータは明確な注釈ガイドラインに従い、さまざまなシナリオで好ましい応答と拒否された応答のバランスの取れた表現を提供する必要があります。
TRLを使用した実装
ORPOは、Transformers Reinforcement Learning(TRL)ライブラリを使用して実装できます。以下は基本的な例です:
from trl import ORPOConfig, ORPOTrainer
<CopyLLMTxtMenu containerStyle="float: right; margin-left: 10px; display: inline-flex; position: relative; z-index: 10;"></CopyLLMTxtMenu>
# ORPOトレーニングの設定
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # 選好最適化の強度を制御
orpo_beta=0.1, # オッズ比計算の温度パラメータ
)
# トレーナーを初期化
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# トレーニングを開始
trainer.train()考慮すべき主要なパラメータ:
orpo_alpha:選好最適化の強度を制御orpo_beta:オッズ比計算の温度パラメータlearning_rate:忘却のカタストロフィーを避けるために比較的小さく設定gradient_accumulation_steps:トレーニングの安定性を向上
次のステップ
⏩ この統合された選好整合アプローチを実装するためのORPOチュートリアルを試してみてください。