a smol course documentation
Tối Ưu Hóa Ưu Tiên Theo Tỷ Lệ Odds (Odds Ratio Preference Optimization - ORPO)
Tối Ưu Hóa Ưu Tiên Theo Tỷ Lệ Odds (Odds Ratio Preference Optimization - ORPO)
ORPO là một kỹ thuật tinh chỉnh mới kết hợp cả quá trình tinh chỉnh theo chỉ thị và tinh chỉnh ưu tiên thành một quy trình thống nhất. Cách tiếp cận kết hợp này mang lại những lợi thế về hiệu quả và hiệu suất so với các phương pháp truyền thống như RLHF hoặc DPO.
Tìm Hiểu Về ORPO
Phương pháp tinh chỉnh như DPO thường liên quan đến hai bước riêng biệt: 1) học có giám sát để thích ứng mô hình với một lĩnh vực và định dạng 2) sau đó là tinh chỉnh ưu tiên để phù hợp với ý muốn của con người
Trong khi SFT hiệu quả trong việc thích ứng mô hình với các lĩnh vực mục tiêu, nó có thể vô tình làm tăng xác suất tạo ra cả phản hồi mong muốn và không mong muốn. ORPO giải quyết hạn chế này bằng cách tích hợp cả hai bước vào một quy trình duy nhất, như minh họa trong hình so sánh dưới đây:
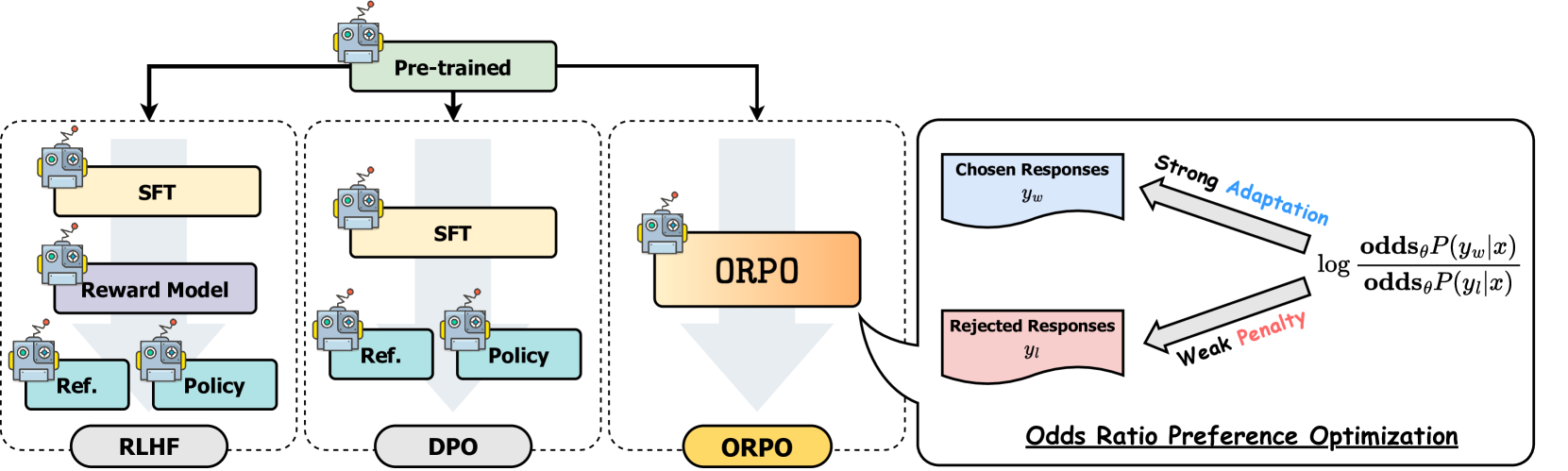 So sánh các kỹ thuật tinh chỉnh mô hình khác nhau
So sánh các kỹ thuật tinh chỉnh mô hình khác nhau
ORPO Hoạt Động Như Thế Nào
Quy trình huấn luyện sử dụng một tập dữ liệu ưu tiên tương tự như chúng ta đã sử dụng cho DPO, trong đó mỗi mẫu huấn luyện chứa một chỉ thị đầu vào cùng với hai phản hồi: một được ưu tiên và một bị loại bỏ. Khác với các phương pháp tinh chỉnh khác yêu cầu các giai đoạn riêng biệt và mô hình tham chiếu, ORPO tích hợp trực tiếp tinh chỉnh ưu tiên vào quá trình học có giám sát. Cách tiếp cận thống nhất này không cần mô hình tham chiếu, hiệu quả hơn về mặt tính toán và bộ nhớ với ít FLOPs hơn.
ORPO tạo ra một mục tiêu mới bằng cách kết hợp hai thành phần chính:
SFT Loss: Hàm mất mát negative log-likelihood tiêu chuẩn được sử dụng trong việc mô hình hóa ngôn ngữ, tối đa hóa xác suất tạo ra các token tham chiếu. Điều này giúp duy trì khả năng ngôn ngữ tổng quát của mô hình.
Odds Ratio Loss: Một hàm mất mát mới giúp phạt các phản hồi không mong muốn trong khi thưởng cho các phản hồi được ưu tiên. Hàm mất mát này sử dụng tỷ lệ odds để so sánh hiệu quả giữa các phản hồi được ưa thích và không ưa thích ở cấp độ token.
Cùng nhau, các thành phần này hướng dẫn mô hình thích ứng với các phản hồi mong muốn cho lĩnh vực cụ thể trong khi tích cực ngăn chặn các phản hồi từ tập các phản hồi bị từ chối. Cơ chế tỷ lệ odds cung cấp một cách tự nhiên để đo lường và tối ưu hóa ưu tiên của mô hình giữa các đầu ra đã chọn và bị từ chối. Nếu bạn muốn tìm hiểu sâu về phần toán học, bạn có thể đọc bài báo ORPO. Nếu bạn muốn tìm hiểu về ORPO từ góc độ triển khai, bạn nên xem cách tính toán hàm mất mát cho ORPO trong thư viện TRL.
Hiệu Suất và Kết Quả
ORPO đã cho thấy các kết quả ấn tượng trên nhiều bài kiểm tra. Trên MT-Bench, phương pháp này giúp mô hình sau tinh chỉnh đạt điểm số cạnh tranh trên các danh mục khác nhau:
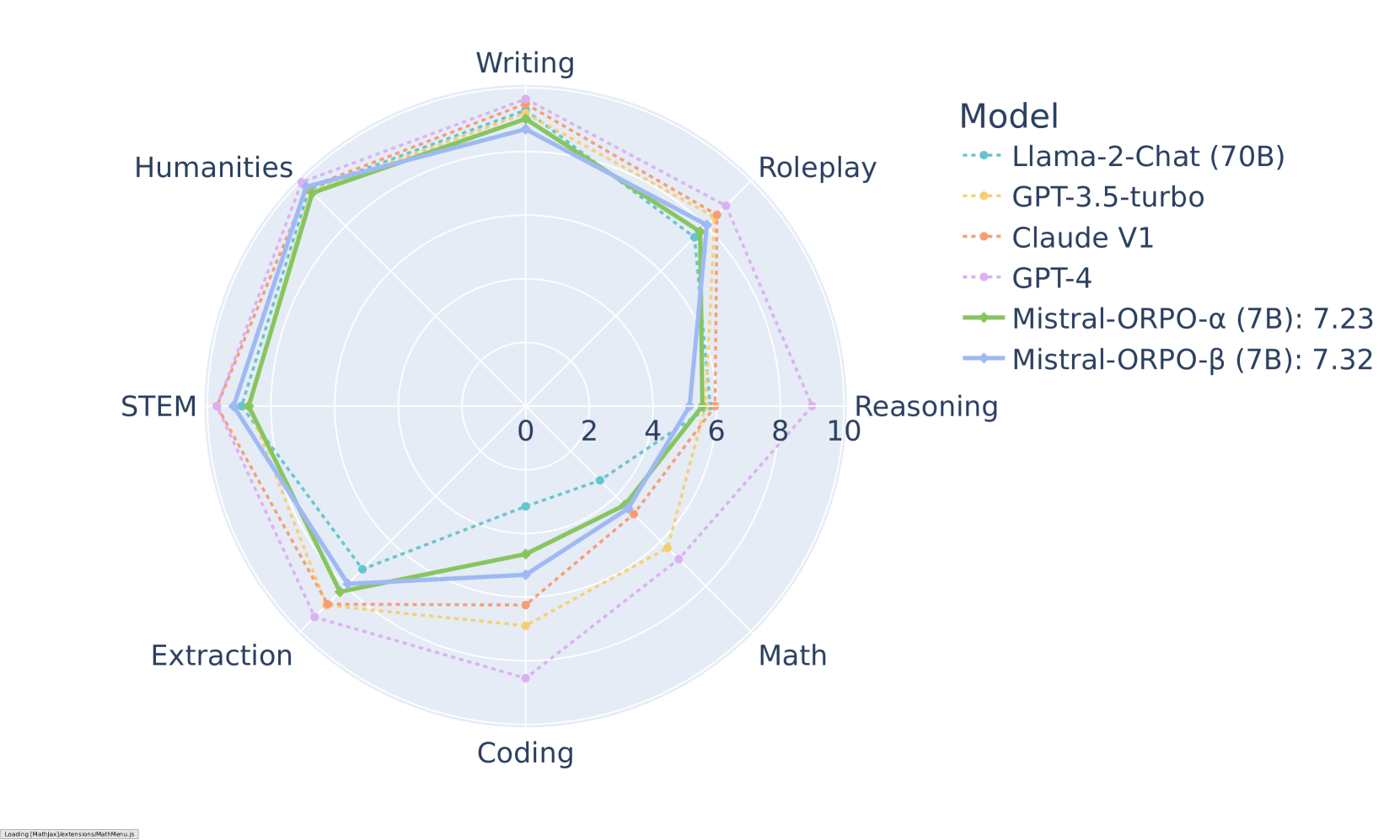 Kết quả MT-Bench theo danh mục cho các mô hình Mistral-ORPO
Kết quả MT-Bench theo danh mục cho các mô hình Mistral-ORPO
So với các phương pháp tinh chỉnh khác, ORPO thể hiện hiệu suất vượt trội trên AlpacaEval 2.0:
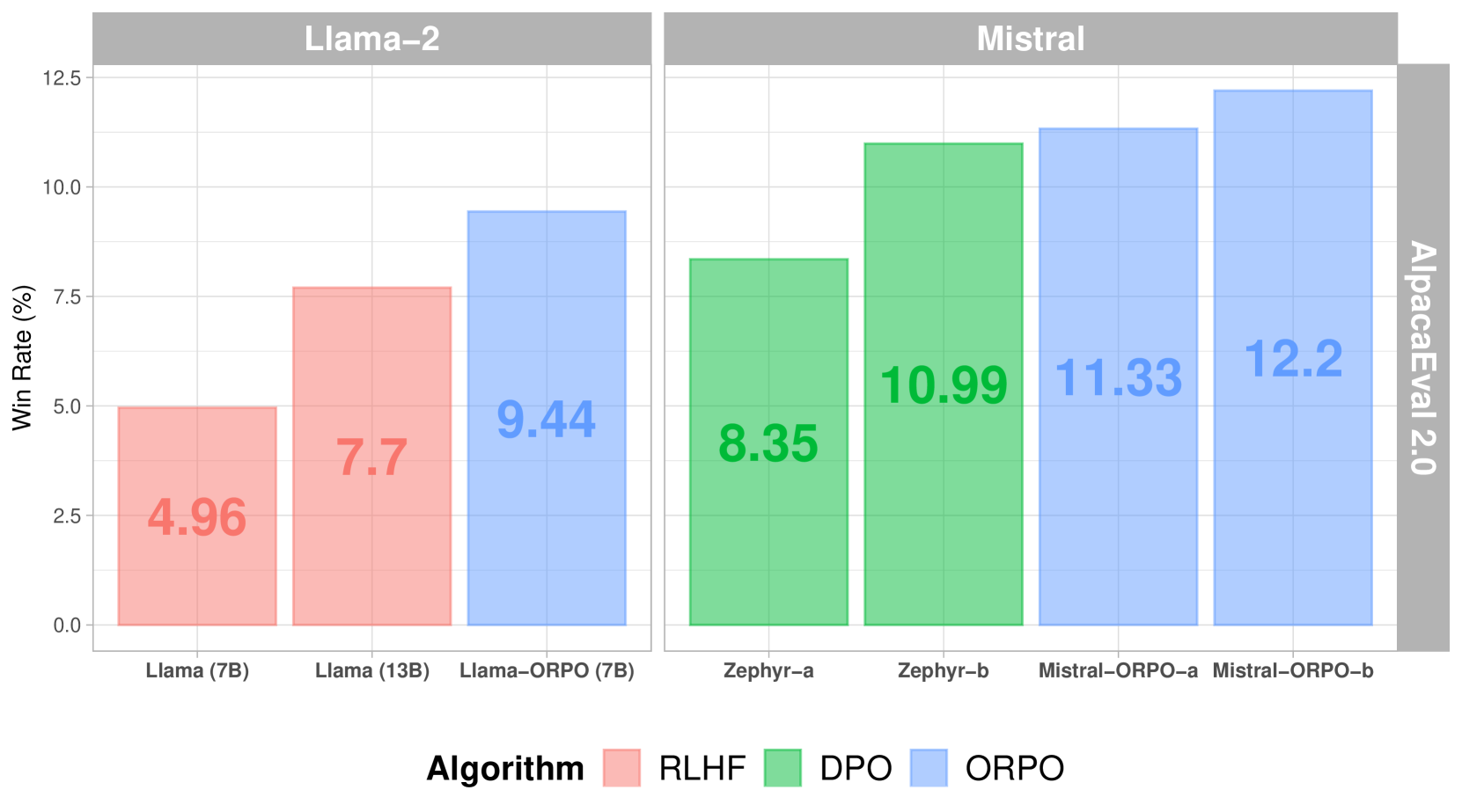 Điểm số AlpacaEval 2.0 trên các phương pháp tinh chỉnh khác nhau
Điểm số AlpacaEval 2.0 trên các phương pháp tinh chỉnh khác nhau
So với việc kết hợp cả SFT và DPO, ORPO giảm yêu cầu tính toán bằng cách loại bỏ nhu cầu về mô hình tham chiếu và giảm một nửa số lần chuyển tiếp (forward pass) cho mỗi batch. Ngoài ra, quy trình huấn luyện ổn định hơn trên các kích thước mô hình và tập dữ liệu khác nhau, yêu cầu ít siêu tham số cần tinh chỉnh hơn. Về mặt hiệu suất, ORPO ngang bằng với các mô hình lớn hơn trong khi cho thấy sự tinh chỉnh tốt hơn với ý muốn của con người.
Triển Khai
Triển khai thành công ORPO phụ thuộc nhiều vào dữ liệu ưu tiên chất lượng cao. Dữ liệu huấn luyện nên tuân theo các hướng dẫn gán nhãn rõ ràng và cung cấp sự đại diện cân bằng của các phản hồi được ưu tiên và bị từ chối trong các tình huống đa dạng.
Triển Khai với TRL
ORPO có thể được triển khai sử dụng thư viện TRL. Đây là một ví dụ cơ bản:
from trl import ORPOConfig, ORPOTrainer
# Cấu hình tinh chỉnh ORPO
orpo_config = ORPOConfig(
learning_rate=1e-5,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_steps=1000,
orpo_alpha=1.0, # Kiểm soát độ mạnh của tối ưu hóa ưu tiên
orpo_beta=0.1, # Tham số cho sự ngẫu nhiên (temperature) trong tính tỷ lệ odds
)
# Khởi tạo trainer
trainer = ORPOTrainer(
model=model,
args=orpo_config,
train_dataset=dataset,
tokenizer=tokenizer,
)
# Huấn luyện mô hình
trainer.train()Các tham số chính cần xem xét:
orpo_alpha: Kiểm soát độ mạnh của thuật toán tối ưu hóa ưu tiênorpo_beta: Tham số cho sự ngẫu nhiên (temperature) trong phép tính tỷ lệ oddslearning_rate: Nên tương đối nhỏ để tránh catastrophic forgettinggradient_accumulation_steps: Giúp ổn định quá trình huấn luyện
Các Bước Tiếp Theo
⏩ Bạn có thể làm theo hướng dẫn trong Hướng dẫn ORPO để triển khai cách tinh chỉnh ưu tiên này.